Introduction
MySQL, Cassandra, HBase, Redis, etc. There are so many databases. One might wonder why do we need so many? In this blog, I will take you through the practical limitations that require us to have these DBs. It should provide you a starting point while choosing a DB for a use-case.
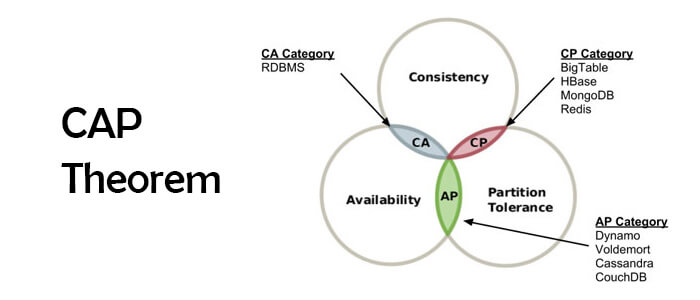
Partition tolerance, Availability, Consistency:
Traditionally and even now, the industry extensively uses RDBMS like MySQL, Postgres, etc. It’s a simple concept to understand and works brilliantly for most use-cases. The problem occurs when we need to scale. RDBMS can only scale vertically. i.e. getting a more powerful machine. But there is a limit to how big a machine you can you. E.g. at the time of this writing AWS provides 3TB RAM and 128 core instances. It sounds big but what if you need to manage billions of active records and millions of reading writes per second? You will need to scale horizontally by using a clustered DB.
In clustered DBs data is partitioned across multiple nodes which are interconnected over a network. In such DBs, under heavy workloads, some nodes may go down or there may be network latency, network failures, etc. The DB is expected to work well even during such cases. It is the partition tolerant nature of DB.
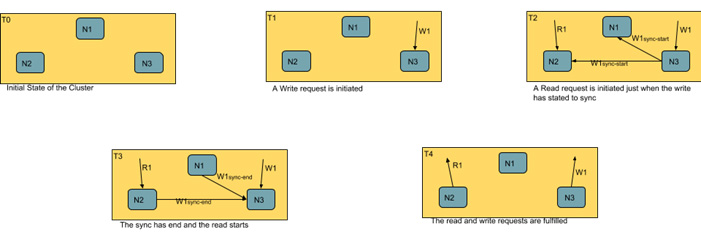
Let's consider a DB table with a partition tolerant nature. It receives a written request on one of its nodes. Now during this operation, a read request was initiated. The DB has two options on how to execute this read operation.
- Wait for the write to complete and its success or failure to be communicated to the cluster. It may then initiate the read.
- Return the partially updated data even when the write was not complete.
In the first case, the DB is waiting for the data to get consistent across the cluster before initiating a read. Such DBs are consistent under network partition. However, if the writer takes too long it may return a timeout error. The diagram below should explain this approach:
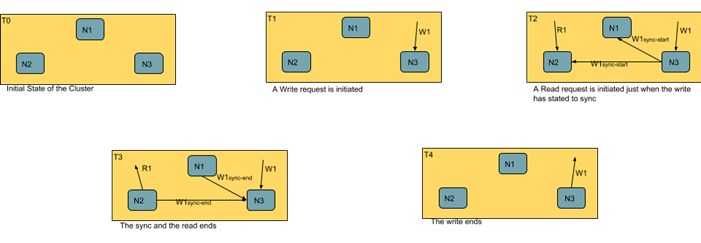
For DBs taking the second approach, they will be providing availability under network partition. As the name implies the data is always available irrespective of whether it's getting modified or not. The diagram below should explain this approach:
We summarize these concepts below:
- Partition tolerance: Return data despite network delays, failures and node failures.
- Consistency: Return the most recent write else and error.
- Availability: Return the data that the DB sees during query execution ASAP.
CAP theorem:
CAP theorem is just the observation we made above. Under network partitioning, a database can either provide consistency (CP) or availability (AP). Note that a DB running on a single node under some number of requests and duration execution time will be provided both consistency and availability.
Here we always mean strong consistency whenever we say consistency. Some databases refer to eventual consistency. Such databases are not consistent under CAP Theorem and will fall under AP.
Choosing a Database:
How will the CAP theorem help us? It depends on your use cases.
Use-case of a CP Database
Let’s say you have a stock brokerage service. A use is supposed to be shown the most recent price. Showing an older price is not desirable. Worse yet if the prices are not consistent then some of the triggers may not hit and the user may suffer a serious loss! In such cases a CP database is desirable. Also, note that since only the stock market writes the new price in negligible time we don’t have to worry about timeouts.
Take another use case where we have to create a customer order history page. Using an AP database will display fewer number orders. It may result in the customer calling customer care to find out what’s going on. However, a CP database will return a ‘please try again later which is OK.
Use-case of a AP Database
Now consider a use case where an eCommerce company has a table with product info of millions of products. A developer is asked to do a bulk update to product prices. In such cases, the update will take a good part of an hour. We will have to wait for all prices to be updated before any read query takes place. It is not desirable as the users of the company will face downtime resulting in loss of business. We will have to return the partially updated data till the update is done. We will have to pick an AP database.
The table below list where in CAP theorem do some of the popular DBs fit in:
| Type | Database |
|---|---|
| CP | Redis, Memcached, HBase, MongoDB (Non Replicated). |
| AP | Cassandra, Dynamo, CouchDB, Riak, Elastic Search, MongoDB (Replicated). |
| CA | MySQL, Postgres. |
As a rule of thumb, while choosing a DB in big data analytics solutions you really should break down your use-case into the read and write durations and whether you have so much data to warrant a clustered DB. If the data and number of requests are not large enough and the queries have low response times consider a CA database. For clustered DB identify cases that can cause your DB to timeout. If you can live with the timeouts go with CP databases. Else the only remaining option is an AP database.



