In this article, we are going to cover some basic text processing when handling text data in natural language processing.
With the help of machine learning, if we are trying to solve some text comprehension or NLU (Natural Language Understanding) problem, it is very difficult to apply any algorithm blindly, so avoid that blind problem. First, we need to understand our data and apply some tits and bits to get insights.
Also, sometimes we are not available with enormous data like 10k data points to apply some deep learning model.
As per my experience, the processing depends on your problem statement and the kind of data available.
So, let’s deep dive into some nitty-gritty processing.
- Understanding the pos tagging from a different library
- Contracting or expanding text for a better and clear understanding
- Spelling checker
I will explain all this with the help of python development and its libraries.
If you have not installed Python on your machine, then just use:
Requirements to be installed:
- Install NLTK -: pip install nltk
- Install Spacy -: pip install spacy
For some other things with nltk just use nltk.download(‘package_name’)

Understanding the POS tagging from different library
Certainly, there are many libraries for the same task in any programming language. Similarly, for text processing/NLP, there are several libraries. Suppose we want to perform NER (Named Entity Recognition), then mostly used library is NLTK. Apart from that, we have some other commonly used libraries like spacy, AllenNLP, etc. For NER, we can use NLTK simple pos tagging and then chunking to extract the entities. Apart from that, we have the Stanford NER model recently given to Stanford University, which both works in a very different fashion, and the same is the case with the spacy inbuilt NER model or pos_tagging.
So, it depends upon the subproblem of your bigger problem statement to use which one. It is according to your suitability.
- import nltk
- nltk.pos_tag(nltk.word_tokenize('hundred thousand'))
## Output: This is the output from NLTK library.
[('hundreds', 'NNS'), ('thousand', 'VBP')]
- import spacy
- nlp = spacy.load('en_core_web_sm')
- doc = nlp('hundred thousand')
- for ent in doc:
- print(ent.text, ent.pos_)
##Output: This is the output from Spacy library.
Hundreds NOUN
thousand NUM
So, you can see from the above outputs that both POS taggers are working differently.
Sometimes it is useful to use the pos tag and then apply the regex/chunking to extract the information, and sometimes use the NER model and, on top of that, apply some regex or rule base to get results according to your requirement.
-
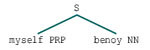
grammar = "NP: {
} # Chunk for abstracting person from opening sentence" - cp = nltk.RegexpParser(grammar)
- cp.parse(nltk.pos_tag(nltk.word_tokenize('myself benoy')))
It is the chunking after pos tagging to extract numbers.
##Output:
##Output -:
['a']
['month']
The above code helps in detecting the duration present with some cardinal numbers like you are paying rent 20k per month etc.
It can be applicable in many use cases. The above code uses NER and then regex and some filtering.
So, you can see it depends upon the problem and how to approach it.
Contraction or expanding text for better and clear understanding
In most cases, we need to replace different writing forms with the standard ones. Such that our model is to interpret it every time in the same way.
Like, some will type, I’m doing well, some will, I am doing well. From these, “I am” is the standard one in front of “I’m”. There can be many cases like this, such as wouldn’t, don’t, etc.
You have to make your list for this kind of item. These are examples of expansion.
Sometimes you are handling abbreviations or chat data such as Twitter/Facebook comments, so you have to replace some short forms like LOL by Laughing out loud, etc.
There are some ways to handle this type of thing either you can make your list if they are repeating and the chance of coming new short forms is less, or you can refer to some websites which are giving full forms of generally occurring short forms according to the domain.
Few you can refer are:
https://www.webopedia.com/quick_ref/textmessageabbreviations.asp
https://www.webopedia.com/quick_ref/Twitter_Dictionary_Guide.asp
More links are available like this
Spell Checker
One thing you can use is spell-checking. This matter is also based on the problem statement. Spell Checker will replace the spelling mistakes with the correct form.
This spell checker is useful in tasks such as question and answer, finding similarities between two statements.
Install pyspellcheker from Pypi using -:
## Output
Correct Spelling for rann word is ran Possible corrections: {'renn', 'crann', 'gann', 'ranh', 'hann', 'rand', 'wann', 'dann', 'mann', 'vann', 'ran', 'ann', 'cann', 'rant', 'rank', 'rain', 'rang', 'bann', 'sann', 'rana'}
Correct Spelling for hapenning word is happening Possible corrections: {‘happening’, ‘penning’, ‘henning’}
Conclusion
In this blog, Python Development Company India describes I hope you can understand what type of processing is necessary for your problem apart from basic processing like punctuation removal, lemmatization, stemming, etc.



