AWS PrestoDB
A quick analytic SQL engine, PrestoDB is a leading solution used to query a huge volume of big data. Presto was developed by Facebook in 2012 to run interactive queries against their Hadoop/HDFS clusters and later on they made the Presto project available as open-source under Apache license. Facebook’s Hive, a query engine that was created to run as an interactive query engine was developed before PrestoDb. However, it was not optimized for high-level performance.
Where can I use Presto?
Presto is capable of running on the top of a wide range of relational as well as non-relational sources, including MongoDB, HDFS, Cassandra, etc.
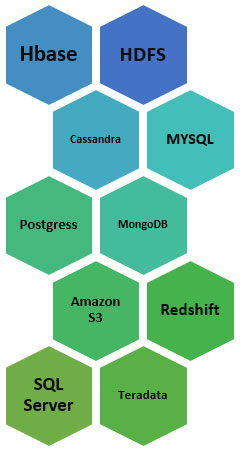
Who uses Presto?
Many reputed companies are currently using PrestoDB in their production environment for analysis of their big data development i.e. Facebook, Airbnb, Netflix, Nasdaq, Atlassian, and many more. Modern internet companies, like Netflix, run almost 35000 queries in a single day, whereas Facebook runs almost 30,000 queries a day. It processes almost Petabytes of data on a day-to-day basis.

Presto Vs Hive
However, Facebook introduced Presto after Hive but it is not a replacement for hive because both have different use cases.
| Presto | Hive |
|---|---|
| Designed for short interactive queries. | Designed for Batch processing. |
| 10-30X faster | Low performance |
| In memory architecture, keeps data in memory. No mapreduce jobs are run. | Hive uses Mapreduce jobs in the background. |
| Not suitable for large workloads because of in memory processing | Suitable for large workloads and long running transformations. |
How Presto works?
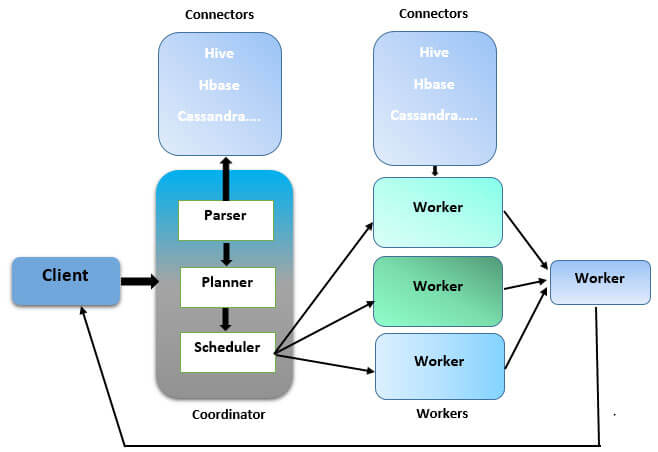
A distributed parallel processing framework, Presto works quite efficiently. It contains one coordinator as well as several workers. Presto client submits SQL query to a coordinator, which parses the SQL queries, analyzes it, and then finally schedules it on multiple workers. It provides support for a variety of connectors, like Cassandra, MongoDB, etc. to get the metadata for creating queries. You can create your custom connector as well. The working nodes eventually retrieve the actual information from the connectors to run the query and finally deliver the result to the client.
The solution supports complex queries and aggregations, along with intricate joins and windows. Presto executes queries in memory without transferring the data from its actual source thus contributing to faster execution by avoiding unnecessary I/O.
Presto in Cloud
AWS is an ideal choice for setting up presto clusters because of high availability, scalability, reliability, and cost-effectiveness and you can launch Presto clusters in minutes on the Amazon cloud. For that matter, Amazon EMR and Amazon Athena are the best way to deploy presto in the Amazon cloud. Amazon Athena allows deploying Presto cluster without doing any node provisioning, cluster tuning, or configuration because it deploys presto using AWS serverless platform. With Amazon Athena, You have to easily point to your data in Amazon S3, define its schema, and start doing analytics on top of it. One of the most prominent reasons for using it is that the client has to only pay for what they use, only when for the time the queries run.
Building First Presto Application Using Athena
Step1: Select Athena
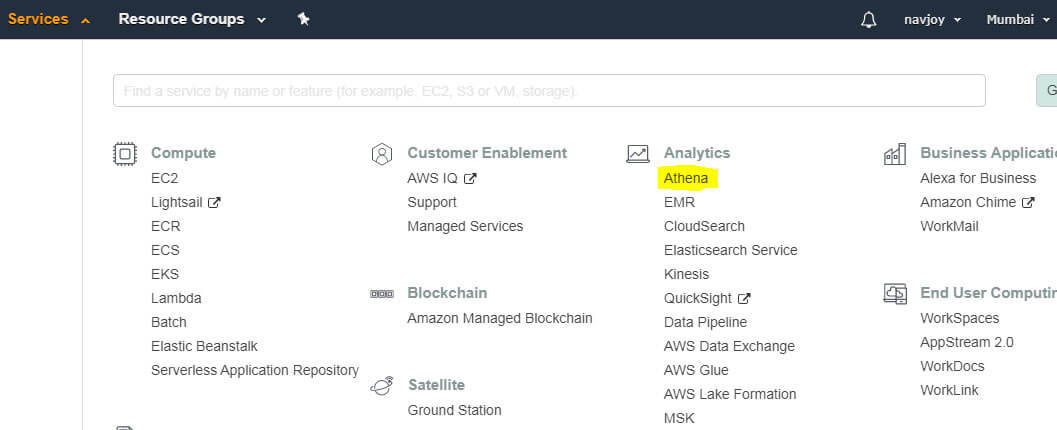
Login to your AWS account using your AWS credentials and from the services tab, select Athena under the Analytics section that will take you to the Athena console.
Step2: Get Started with Athena
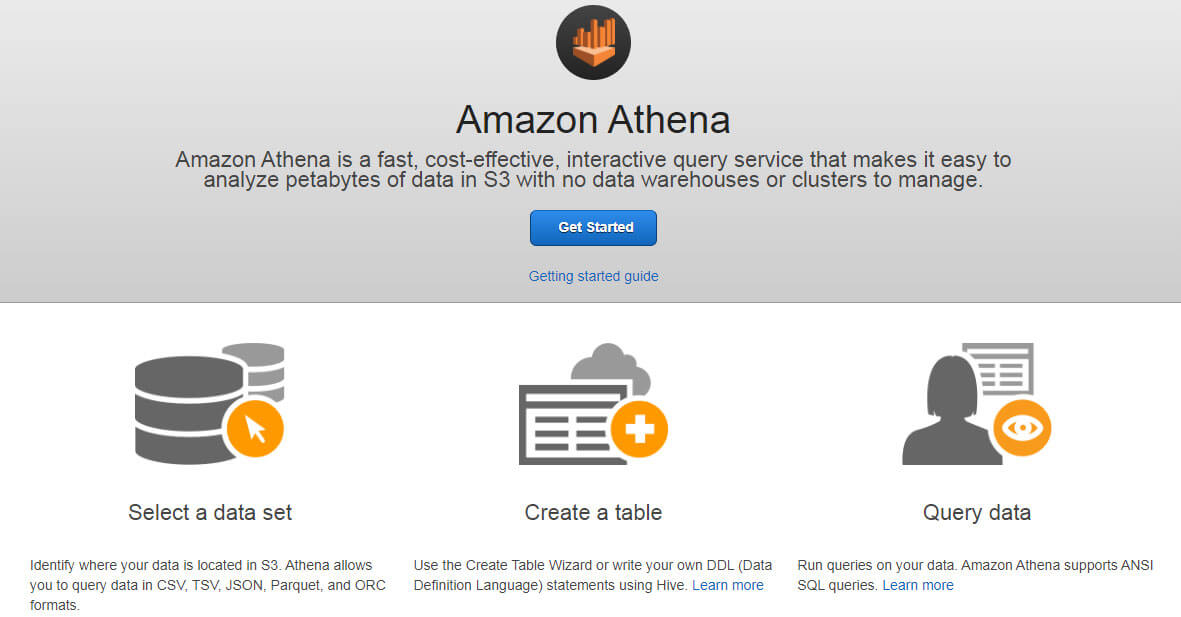
Athena enables the users to choose their data for analytics from Amazon S3. The console is capable of reading the data in several different formats, like JSON, CSV, TSV and more. It is also possible to make schema over the data. Afterward, the data can be queried using SQL/Hive queries to get valuable insights. Select the get started button to move further.
Step3: Athena Editor
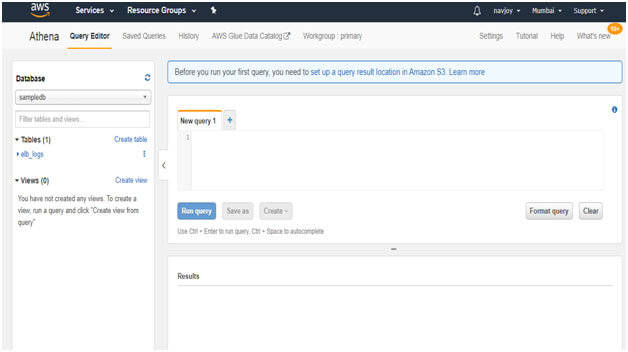
Athena editor is capable of running interactive queries (SQL/Hive DDL) on the data which is stored in Amazon S3. Also, there isn’t any need for clusters or data warehouses. However, before the query is run, the Amazon S3 location needs to be set up properly. It is done to store query results as well as the metadata information for every query. Click on the link to set up.
Step4: S3 Setup
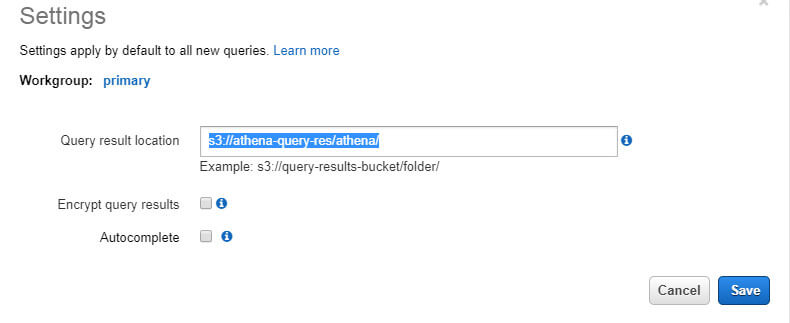
After you click on the link, this setting window will appear where you have to provide the S3 bucket location in, which you want to store your query results, also you can choose to encrypt query results. A bucket titled “Athena-query-res” is created. Under it, I also created a folder named “Athena”. Query results can be saved. Click Save.
Step5: File upload to S3
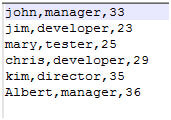
I have uploaded employee.txt, which contains the above data (name, designation, and age) to my S3 bucket for analysis. We will create a table on top of this data using Athena editor.
Step6: Create Database/Table
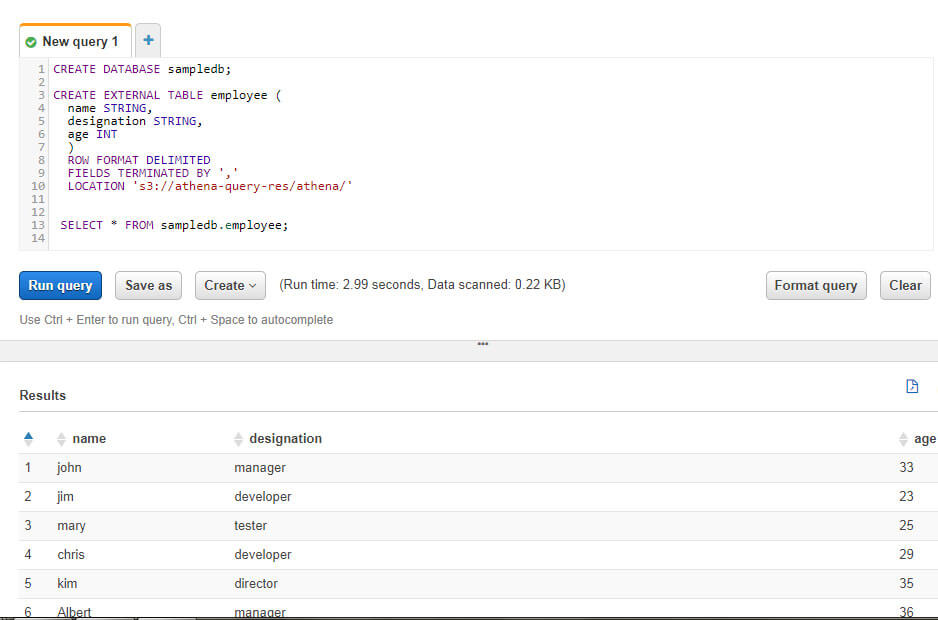
The next step is to create a database and create a table to represent my data. I created a database called “sampledb”, which is visible in the above image. I also created a table called the employee to showcase the data that is uploaded on S3 before. To create an external table, I used Hive DDL. It is pointed to the S3 location. Afterward, I choose all the data to view data in the editor.
Step7: Query Data
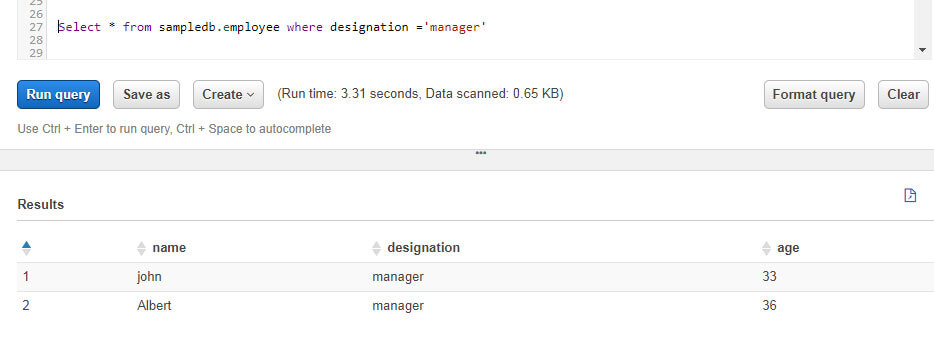
Since my data & schema are in place, now I can fire any query on top of that data to perform some analytics using either SQL or HQL. In the above example, I fired a query to find out all employees whose designation is the manager. Similarly, you can perform aggregation, joins, window operations on top of this data.
Step8: View History
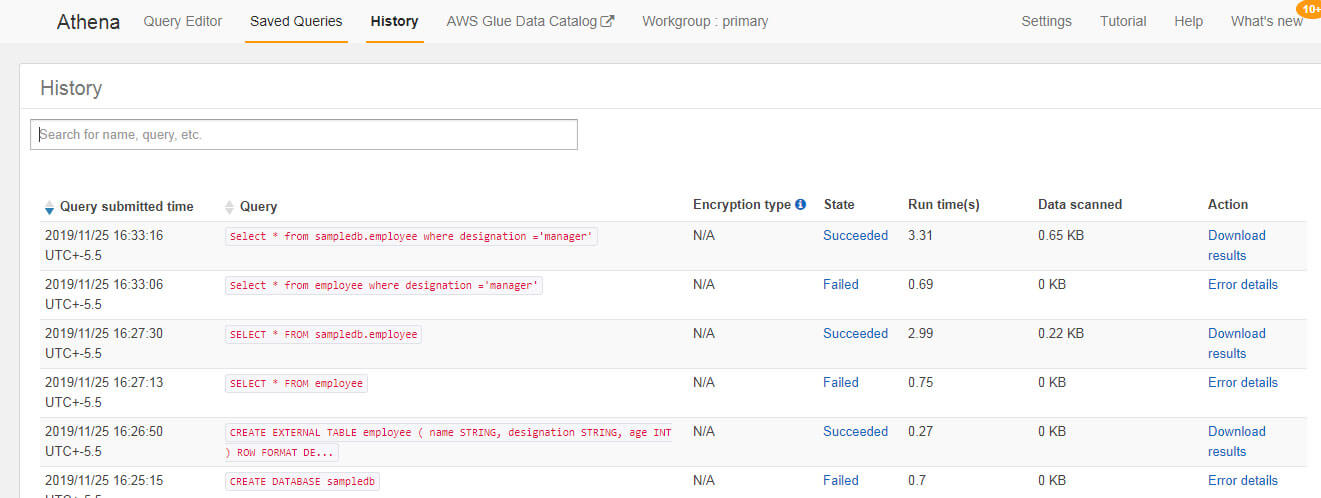
Use the history tab to see all the queries run earlier. Using the History tab, you can also view error details, query runtime, query status whether failed or succeeded, query submission time and download query results. Although we have taken very small data to query, presto can also be used on petabytes of data.
Presto with AWS Glue
AWS Glue offers a combined metadata repository across plenty of data sources as well as formats, like Athena, Redshift and more. It can be integrated with Presto; it will act as a data megastore. AWS Glue is capable of automatically inferring the schema from the source data in Amazon S3. Also, it is important to store the related metadata in Data Catalog.
ConclusionPresto is blurring the boundary of analytics on relational & non-relational data sources by supporting both in the same manner henceforth making its mark in the market very quickly. The adoption of Presto by AWS has made it even more viable for companies moving to cloud infrastructure.

Recent Blogs
Categories


