Recently, there has been a war going on between several big data processing frameworks such as Apache Spark, Apache Flink, Apache Storm, etc. but it’s hard to say which one is better since these frameworks are evolving at a very fast pace and come with their pros and cons. Therefore, a need for a framework arises that can provide a clean abstraction over distributed programming model so that we can focus on application logic rather than underlying frameworks. Apache Beam introduced by google came with the promise of unifying API for distributed programming. In this blog, we will take a deeper look into the Apache beam and its various components.

Apache Beam
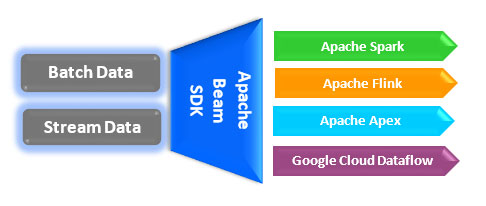
Is a unified programming model that handles both stream and batch data in the same way. We can create a pipeline in beam Sdk (Python/Java/Go languages) which can run on top of any supported execution engine namely Apache Spark, Apache Flink, Apache Apex, Apache Samza, Apache Gearpump and Google Cloud dataflow(there are many more to join in future). With Apache beam, you can apply the same operations whether it is bounded data from some batch data source like HDFS file or it is unbounded data from some streaming source like Kafka.
How does the apache driver program work?
First, create a Pipeline object and set the pipeline execution (which runner to use Apache Spark, Apache Apex, etc.).Second, create Pcollection from some external storage or in-memory data. Then apply PTransforms to transform each element in Pcollection to produce output Pcollection. You can filter, group, analyze or do any other processing on data. Finally, store the final Pcollection to some external storage system using IO libraries. When we run this driver program, it creates a workflow graph out of the pipeline, which then executes as an asynchronous job on the underlying runner.

Beam Transformations
Pardo
Pardo transformation applies processing function on each element in PCollection to produce zero, one, or more elements in resulting PCollection. You can filter, format, compute, extract and type-convert elements in PCollection using the Pardo function. To apply Pardo, you need to create a class extending DoFn that will contain a method annotated with @ProcessElement, which function will contain the processing logic to apply on each element of PCollection and give back the result.
GroupByKey
GroupByKey group all values associated with a particular key. Suppose we have the below data where the key is the month, value is the name of the person whose birthday falls in that month, and we want to group all people whose birthday falls in the same month.

To use GroupByKey on unbounded data, you can use windowing or triggers to operate grouping on a finite set of data falling in that particular window. For example, if you have defined a fixed window size of 3 minutes, then all data that comes in 3 minutes span will be grouped based on the key.
ALSO READ
CoGroupByKey
CoGroupByKey joins two or more set of data that has the same key. For example, you have one file that contains the person's name as a key with phone number as value and a second file that has the person's name as a key with an email address as value. So joining these two files based on person name using CoGroupByKey will result in a new Pcollection that will have person name as key with phone and email address as values. As discussed in GroupByKey, for unbounded data we have to use windowing and triggers to aggregate data using CoGroupByKey.

To use GroupByKey on unbounded data, you can use windowing or triggers to operate grouping on a finite set of data falling in that particular window. For example, if you have defined a fixed window size of 3 minutes, then all data that comes in 3 minutes span will be grouped based on the key.
Flatten
Flatten merges list of PCollection into single PCollection.
Partition
As opposite to Flatten, it splits a single PCollection into multiple smaller PCollection according to the partition function that the user provides.
Pipeline IO
Apache beam comes bundled with numerous IO libraries to integrate with various external sources such as File-based, Messaging and database systems to read and write data. You can also write your custom libraries.
Read transforms read from an external source such as File/Database/Kafka to create a PCollection
Write transforms write the data in PCollection to some external source such as database/filesystem.
Windowing
Windowing is a concept of dividing data based on the timestamp of the element. Windowing becomes especially critical when you are working with unbounded data and aggregated transformations like groupByKey and CoGroupByKey because to aggregate data based on some key, you need a finite set of data.
You can define different kinds of windows to divide the elements of your Pcollection.
Fixed Time Windows:
It is the simplest, which has a fixed size with non-overlapping windows. Consider a window with a 5-minute duration, which means all the elements in unbounded Pcollection that fall between 0:00 mins to 0.05 mins will be captured in the first window; all elements that fall between 0.05 to 0.10 mins will be captured in the second window and so on.
Sliding Time Windows:
Sliding time windows are overlapping windows that have a window duration, which defines the time interval for which we want to capture data and has a period that defines when a new window will start. For example, suppose we have a sliding window that has a window duration of 5 minutes and a period of 20 seconds, it means each window will capture five minutes' worth of data, but a new window will start every twenty seconds.
Per-Session Windows:
A session window function defines windows that contain elements that are within a certain gap duration of another element. Session windowing applies on a per-key basis and is useful for data that is irregularly distributed concerning time. In the below code snippet, each session will be separated by time duration of at least 10 minutes.
Single Global Window:
By default, all elements in your Pcollection are assigned to a single global window. You can use a single global window with both bounded and unbounded data.
No doubt, Apache beam is the future of parallel processing and its “write once and execute anywhere” is making it even popular among big data development solutions ecosystem. Currently, there is limited support and integration with backend execution runner but in the future more and more frameworks will get integrated to make distributed programming more stable and unified.

Recent Blogs
Categories


