For any developer, he must be able to easily test his code. The comfort of easy testing and debugging improves our efficiency. However, the Big data spark coders (at-least the ones I have worked with) seem to be oblivious to this simple fact. Following are some of the issues faced:
- Depending on the problem you will need to shift between multiple external systems (S3, HDFS, Kafka, etc) to validate and debug.
- We are consuming external resources for development purposes which increasing cost.
- You may be using a copy of production data or worse production data itself. Someone making a mistake may lead to the production data getting corrupted.
- There is a possibility that the production copy may not cover all your use cases.
- Depending on your data you may have to run the jobs for a long time on huge compute resources.
In conclusion, the big data developer is wasting his time. Also increasing cost by using external system resources.
This blog post is intended for big data developers facing such issues. I will take you through a simple approach for big data solutions to speed-up the process of testing and debugging spark jobs.
Scope
It is assumed that you are familiar with Spark. Practically other than unit testing we may also need to do integration tests and load tests. Such cases like connectivity with external systems, scalability under load, etc. are not unit testing and are beyond the scope of this blog.
The Problem
The following code should approximate the spark job that gets usually written.
package com.udaykale.blog
import org.apache.spark.sql.SparkSession
class SampleJob {
def main(args: Array[String]): Unit = {
val jobName = "SampleJob"
val filePath = "File path to production data"
val topic = "sample-topic"
val spark = SparkSession.builder()
.master("local[2]")
.appName(jobName)
.getOrCreate()
val inputDF = spark.read.parquet(filePath)
import spark.implicits._
// Usually we have more
val outputDF = inputDF.where($ "id" === 1)
outputDF.writeToKafka(topic)
}
}
If you want to test this code you will need
- To connect with file storage systems like S3/HDFS.
- Connect with Kafka.
- Proper test data in S3 to cover all use-cases.
- Some place to run this job.
Unit testing
In unit testing, we test units of programs like methods, utilities, services, etc. Any external systems are mocked with a similar implementation. E.g., in the above snippet, we can refactor the code to support reading from S3 in production and reading from local files for unit test purposes.
Note that and code related to Kafka initialization was skipped. In writing unit tests we don't need to deal with external systems anyway. We only need to concern ourselves with the logic testing of the job. Later we will mock it.
The Solution
We will, to make the code testable, refactor the code as follows.
package com.udaykale.blog
import org.apache.spark.sql. {
DataFrame, SparkSession
}
object SampleJob {
def main(args: Array[String]): Unit = {
val jobName = "SampleJob"
val filePath = "Some file Path"
val topic = "sample-topic"
val spark = SparkSession.builder()
.master("local[2]")
.appName(jobName)
.getOrCreate()
val outputDF = doSomeThing(spark, filePath)
outputDF.writeToKafka(topic)
}
def doSomeThing(spark: SparkSession, filePath: String): DataFrame = {
val inputDF = spark.read.parquet(filePath)
import spark.implicits._
return inputDF.where($ "id" === 1)
}
}
For us now the doSomeThing method is the unit to test. The returned dataframe can be used for assertions in unit tests or writing to external systems like Kafka on production. We will now define a few environments, for convenience's sake.
package com.udaykale.blog
object Environment {
val LOCAL = 1;
val DEV = 2;
val PROD = 3;
}
Next, we will define a FileService trait. A ServiceFactory will return different implementations of this trait depending on the environment.
package com.udaykale.blog import org.apache.spark.sql. {
DataFrame,
SparkSession
}
trait ServiceFactory[T] {
protected def map(): Map[Int, T];
def instance(env: Int): Option[T]=map().get(env);
}
trait FileService {
def read(spark: SparkSession, filePath: String): DataFrame;
def write(spark: SparkSession, filePath: String, df: DataFrame);
}
object FileServiceFactory extends ServiceFactory[FileService] {
override protected def map(): Map[Int, FileService]=Map(Environment.DEV -> FileServiceCSV, Environment.LOCAL -> FileServiceDummy, Environment.PROD -> FileServiceS3Parquet)
}
object FileServiceS3Parquet extends FileService {
override def read(spark: SparkSession, filePath: String): DataFrame= {
spark.read.parquet(filePath)
}
override def write(spark: SparkSession, filePath: String, df: DataFrame): Unit= {
df.write.parquet(filePath)
}
}
object FileServiceCSV extends FileService {
override def read(spark: SparkSession, filePath: String): DataFrame= {
spark.read.csv(filePath)
}
override def write(spark: SparkSession, filePath: String, df: DataFrame): Unit= {
df.write.csv(filePath)
}
}
object FileServiceDummy extends FileService {
override def read(spark: SparkSession, filePath: String): DataFrame= {
import spark.implicits._ Seq( ("1", "Tom"), ("2", "Dick"), ("3", "Harry")).toDF("id", "name")
}
override def write(spark: SparkSession, filePath: String, df: DataFrame): Unit= {
df.show(false)
}
}
I have defined the FileServiceDummy for explanation in this bog. Ideally, you will use the FileServiceCSV with your test data residing in your local machine in CSV format.
We will use this in our job as follows:
package com.udaykale.blog
import org.apache.spark.sql. {
DataFrame, SparkSession
}
object SampleJob {
def main(args: Array[String]): Unit = {
val jobName = "SampleJob"
val filePath = "Some file Path"
val topic = "sample-topic"
val env = Environment.PROD
val spark = SparkSession.builder()
.master("local[2]")
.appName(jobName)
.getOrCreate()
val fileService = FileServiceFactory.instance(env)
if (fileService.isEmpty) throw new NullPointerException("Instance of File Service not found")
val outputDF = doSomeThing(spark, filePath, fileService.get)
outputDF.writeToKafka(topic)
}
def doSomeThing(spark: SparkSession, filePath: String, fileService: FileService): DataFrame = {
val inputDF = fileService.read(spark, filePath)
import spark.implicits._
return inputDF.where($ "id" === 1)
}
}
As you can see, we have mocked the file reading code, which can be selected based on the run time. By default, it will try to read the parquet file since we have defined the environment as production.
For unit testing, we will use the scala test library. To use this add
libraryDependencies += "org.scalatest" % "scalatest_2.11" % "3.0.5"
to the project's .sbt file.
Following is the unit test for our doSomeThing method.
package com.udaykale.blog
import com.udaykale.blog.SampleJob2.doSomeThing
import org.apache.spark.sql. {
DataFrame, SparkSession
}
import org.scalatest.FlatSpec
class SampleJobTest extends FlatSpec {
"doSomeThing"
should "Do Some Thing" in {
val jobName = "SampleJob"
val filePath = "Some file Path"
val topic = "sample-topic"
val env = Environment.LOCAL
val spark = SparkSession.builder()
.master("local[2]")
.appName(jobName)
.getOrCreate()
val fileService = FileServiceFactory.instance(env)
if (fileService.isEmpty) throw new NullPointerException("Instance of File Service not found")
val outputDF = doSomeThing(spark, filePath, fileService.get)
import spark.implicits._
val expectedDF = Seq(
("1", "Tom")
).toDF("id", "name")
assertDF(spark, outputDF, expectedDF)
}
def assertDF(spark: SparkSession, actualDF: DataFrame, expectedDF: DataFrame): Unit = {
val actual = dfToStringSeqArray(spark, actualDF)
val expected = dfToStringSeqArray(spark, expectedDF)
if (actual.length != expected.length) assert(false)
actual.zip(expected)
.foreach(actualExpected => {
if (actualExpected._1.length != actualExpected._2.length) assert(false)
actualExpected._1.zip(actualExpected._2).foreach(zipValue => assert(zipValue._1 == zipValue._2))
})
}
private def dfToStringSeqArray(spark: SparkSession, x: DataFrame): Array[Seq[String]] = {
import spark.implicits._
x.map {
row => row.toSeq.map(value => value.asInstanceOf[String])
}
.collectAsList().toArray.asInstanceOf[Array[Seq[String]]]
}
}
The test class extends the FlatSpec class. This class provides is a BDD style unit test functionality. Since we have selected the environment as LOCAL the factory will then return the FileServiceDummy implementation. You can switch to DEV to fetch it from a local CSV file. The assertDF utility will test the actual and expected dataframes.
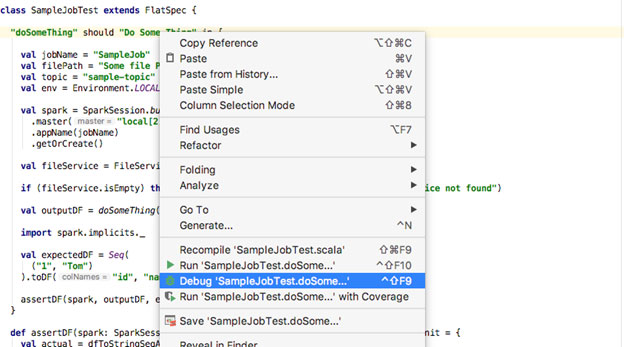
To run this I use IntelliJ since it's convenient to debug. Right-clicking on the test to run, should give you the necessary options.
Advantages of this approach
- No connectivity with external systems required.
- It's easy to validate and debug since the input-output is confined within our machine.
- The data can be customized for testing and we can cover more use-cases because of it.
- It's easy to switch between different environments.
- We save costs by using our machine only.