Introduction to Cloud-based Service
The design of a cloud-based file storage service like Dropbox or Google Drive or design a file storage service whether it is Google Drive or Microsoft OneDrive or Dropbox, Design will almost be the same. And is always based on the requirements. So, let’s first discuss those requirements.
Requirements Gathering
Before going into the requirement storage phase, you need to understand one thing about file storage service system design. It is a very tricky question, and there are so many different things that you have to consider.
Functional Requirements
1. User Account:
Let’s first discuss the functional requirement the very first functional requirement is the user needs an account to use the file sharing service. So, an account and what it also means is that we can have two types of users.
We can have free users, and we can have premium users where we can assume that the free users are using our service in a limited capacity. For example, they might have limited storage available as compared to the storage space that is available for the premium users. Similarly, the network bandwidth that we provide to the free users might be way less than the network bandwidth that we provide to the premium users.
2. Specifying the Root Directory
The second requirement is that the user can have multiple devices and now what he can do is he can specify a root folder in any device. And whatever files and folders he creates in that root folder that is get replicated to all the other user devices. Right now, we’re assuming the maximum file size we’re going to support is 10GB.
3. Sharing the Files among other use accounts
Another important requirement is that the user should be able to share files and folders with other users. So by file folder sharing, that means, basically the original owner of the files and folders has the desired access. But when a user shares files or folders with other users, he can either give them access to them, or he can give them access to them. Only the original owner of the file has access to it or the folder has access to it.
Users can also be the ones who can share the files and fold them up with other users, user can only share a file or folder which he owns user cannot share a file or folder with other users if he is not the original owner of that file or folder.
4. Access Control:
The owner has full access, and full access means he can read-write the files, he can delete the files, and he can share the files while the other users can just read/write or read-only. Other users can have either read-write or just read-only access to the files and folders.
5. Imposing Storage Limit and Allowing Offline Updates of Files/Folder
The other requirement is the system should support storing files and folders up to a certain limit only. And once a user has reached his file storage limit, the system should not allow any other files. Also, the system should allow offline creation of files or offline update or deletion of files and folders.
What it means is that while the device is offline the user can go and either modify a file or delete a file or even create a new file. When that device gets connected with the Dropbox service, then all those changes get replicated to all the other devices for the user.
6. Out of The Box/Extended Requirement
There can be some other extended functional requirements, for example, the system should allow multiple versions of a file. And the user should be able to recover the file to a previous version if he wants, however, this requirement is very tricky because it imposes several design constraints and questions as follow.
The first question that comes to mind is how the versioning should be performed whether it is from an update to another update or it’s a daily snapshot of all the updates. Also, how will it affect the files and folders that are shared between different users, if the user with read-write access decides to revert some changes to the file? How those changes will be copied to all other user’s devices.
Whether the total space used by each version or snapshot is calculated as the total space used by the user and in that case what should be done after the user reaches his limit. Should we start dropping old versions, or should we stop creating newer versions, etc?
The system should be able to keep track of all the analytics related to storage and network consumption. Also one of the extended requirements is which comes into the picture when you start allowing shading of files. And folders among users what will happen if two users try to update the same file and if a conflict arises because of that how you will resolve that conflict.
Another important requirement is data security the risk of data read during transmission can be mitigated through encryption technology encryption in transit protects data as it is being transmitted to and from the device to the cloud or vice versa. Encryption at rest protects data that is stored in the cloud service. Another requirement can be providing such a facility so that a user can able to go and search his files and folders.
Non-Functional Requirements
1. Highly Scalable and Fault-Tolerant System
So, these are the different functional requirements. The system needs to be highly available and fault-tolerant. Another requirement is the system should be highly scalable. And it should scale with increasing load or increasing users and data.
2. Synchronization & Latency & Bandwidth
The second requirement is that file synchronization should use minimal network bandwidth, and file transfer should happen with minimal latency. File synchronization should require minimal bandwidth, and minimal latency are very important.
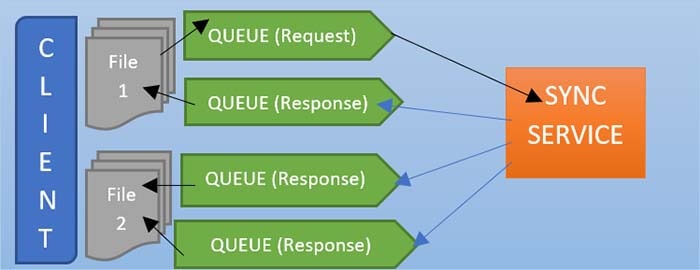
Whatever information is required what is received – should be broadcast all of those messages to the response queues. What happens is all the same metadata information will be sent to the response queue one response Q2 and response q3 that information will be there inside this queue. So now I think the queue helps you to buffer these updates.
If these two types of requests are now disconnected the message will be in the queue. And will never be lost if it is an asynchronous service, this should be called directly to the client somewhere via HTTP, which does not work or not.
So, whether there is all the meta-information in the response queue, and whenever we know that these lines are connected to the servers, this meta-information will be distributed. As soon as this price receives that metadata information, they know what to do with that, so they know the URL from where they should fetch those chunks and then update their respective files. If they don’t have the files, they will download the file and keep it in sync. Otherwise, they will download the chunks, which were updated from the client one, and update the file.
Because due to these two requirements, we will decide to upload every file by first dividing it into small segments or chunks. And this will enable us to only upload or download modified chunks of a file and also if uploading or downloading of a chunk failed. We only need to retry the upload or download of that particular chunk instead of retrying the upload or download of the complete file.
3. ACID Requirement
The Dropbox service guarantees acid requirements for the files that are stored, with the Dropbox service acid, which stands for atomicity consistency, isolation, and durability. Let’s suppose in one of your devices a file was changed from one version to another, and those changes get replicated to all the other devices. If you go to the second device in the second device the file which was changed in the some in the first device is now getting all the changes that will move it from the first version to the second version. And it’s possible that to move from the first version to the second version there might be multiple chunks that got modified.
All those chunks get uploaded separately, and then on the second device, they get downloaded separately. The issue is that if you apply one chunk at a time the user may see the file on that device in a transient state, where he will see the first chunk get applied then the second chunk applied. And so on, however, it will break our atomicity requirement the atomicity means either all or nothing. So, the user should not see all the transient changes while we are moving a file from one version to another version.
So how do we achieve this? The requirement of Dropbox service is that in our client-side Dropbox application we will first apply all the changes to our temporary file and that file can be stored in a temporary folder or maybe in the same folder. A different name and that file can be hidden from the user, and once all the changes to the file have been applied we can use the atomic file, such as a link or name, to manually switch a temporary file with the original file.
Different values that don’t make sense together, for example, if a user has deleted a file on one device, then other users or devices, should not see that file getting partially deleted first, this is an inconsistent state that would cause errors if someone tried to redirect the partial file this is different from the replication consistency which we are going to discuss later where an update happens in a device but takes some time to get replicated to other devices in acid properties stand for isolation means transactions that are happening concurrently, will not affect each other in the case of Dropbox/GDrive service.
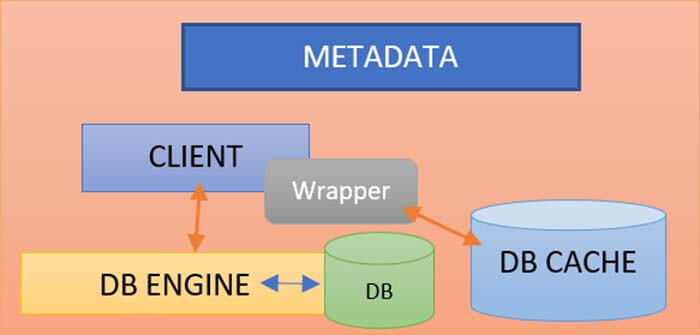
4. Metadata Storage Requirement
We may use any database to store metadata information. If we only use MySQL or Oracle DB, we may face multiple problems. Because continuing to standardize the schema every time is a significant burden.
Our system has to handle this case also where updates can happen to a file and both these on two different devices, and those devices can be offline and now when those two devices get online then those updates will flow to each other. And it could cause conflicts, and then we need some way to resolve those conflicts which is a hard problem. Now in acid properties is the durability it means that once a change has been made and uploaded then it will not be lost.
For example, if a file has been created to a device and synced to the remote file storage then that file should not be lost this does not imply that another operation, later on, will not modify or delete the file it just means that the changes are available to the next operation to work with as necessary. It also implies that any lights that happen to a Dropbox/GDrive service should be replicated to multiple data centers even across continents to make sure that any large-scale disaster. For example, an earthquake or flooding, or fire that can wipe out the entire data center does not cause data loss here.
Replication consistency
- The replication consistency is different than the consistency in the acid requirement what it means here is that when an update happens on the device, it will take some time to that get replicated to the file storage service. And also to other devices, and the replication consistency will be eventual.
- So, we cannot have a strong replication consistency here due to the nature of the problem that we are allowing offline updates to a file. It means a user can update some files on a device that is offline. And then only when the device gets online then the changes will get replicated to the fastest service. And from there, it could go to other devices only when those devices are online as well.
- So, the replication consistency will be eventual in the case of the Dropbox/Google Drive service, and please do not confuse the replication consistency with the consistency here in the asset requirements.
API Designing
Let’s discuss some APIs that our service will expose so the very first API is the upload file.
File Upload API
It takes user API token, file metadata, and file content. The file content could be a stream of different chunks for the file.
File Update MetaData API
The upload file will return a file id. It will take our token as input file id and then file metadata. And what could be the file metadata is like file creation time, update time or file size, etc.
Update file API
It will take the user API token as input, then file id, metadata changes, and modified segments. Modified segments are just changing the input stream for all the different chunks or segments of the file that are changed.
Delete/Remove File API
This API is to delete the file which will take input as user API token and file id.
Files and Folders Share API
This is another API to share files or folders. This API will take the API user token, file or folder id, another user id, and ACL Rules/set of permissions. This ACL (access control Rules) can be redirected or read.
Revoke Sharing API
It is the API for stopping sharing, and it can take a user token and a namespace id. The name space id, which we would receive from the share Files/Folder API. The name space the concept I will hear later, and of course, a user can always list all the shared namespaces.
Namespaces:
- Home Namespace
- Shared Namespace
- Proxy Namespace
Dropbox/GDrive namespace means the unique ID. So, we have three types of namespaces. It was essentially a home namespace when a user X shared a file with user Y, we create a shared namespace for user X and a proxy namespace for user Y, and this proxy namespace points to the shared namespace.
If you want to design a global file-sharing system, you can hire Java developers. They are well versed in designing and developing any kind of service with high efficiency.
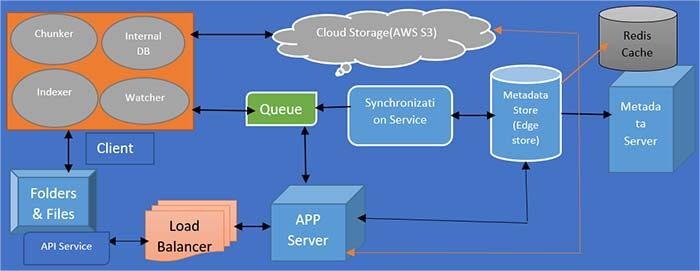
High-Level System Designing
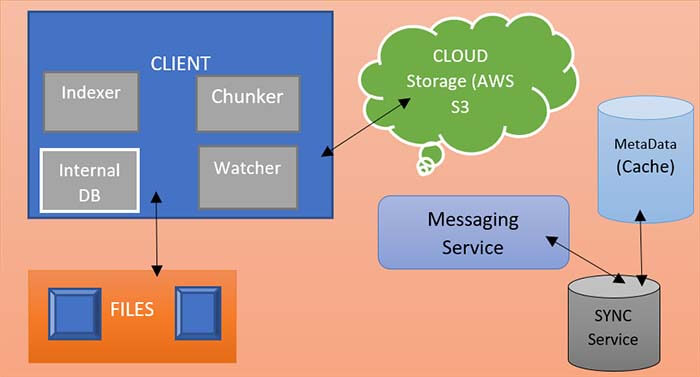
Here, Java developers are going to explain the High-level design of Dropbox or Google Drive service. So on my right side, we have a client application, and the client application itself comprises five different components.
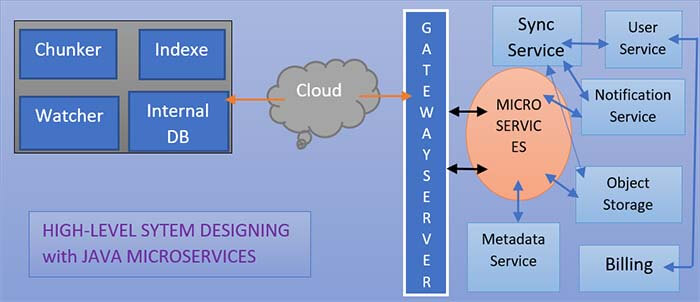
Watcher
The watcher component in the client application is looking for all the file folder changes that are happening under the root folder that the user has specified to be shared with all the other devices and with the Dropbox/GDrive service.
Chunker
Here, we have to use chunker. The chunker is a component that is responsible for breaking a file into multiple chunks, and it is also responsible for calculating the cryptographic hash for each chunk. The cryptographic hash function that we can use could be the sha-256 or sha-512 algorithm.
Indexer
We have to use a file indexer here. The file indexer stores an index of all the files that are stored within that root folder that the user has specified with the Dropbox/GDrive service.
Internal Database
The internal database is a file database stored in the client app where the indexer stores all the metadata information about the file and all its different chunks. The Dropbox/GDrive client application can use any lightweight database like SQLite or Berkeley database etc, for internal DB.
Synchronizer (SYNC Service)
The sync service in the client application is the one that is responsible for syncing all the changes that happen on the device to the remote Dropbox/GDrive service or vice versa.
The synchronization service is a service that is the main component that is talking with the synchronizer here in the client application any changes that happen on a device the synchronizer informs those changes to the synchronization service.
We are going to divide every file into small chunks or segments, and two reasons and the reason why we are doing that is that we have two non-functional requirements that cause us to upload or download a file in the form of chunks. The question is what would be the suitable chunk size should we use? Whether to use 4KB, eight KB or 64 kilobytes, or 1MegaByte. What would be the most suitable chunk size, and how to calculate an optimal chunk size for the file?
Microservices:
So this was the client application and if you see in the above image that the client application is communicating with the Dropbox/GDrive service over the internet. And on the right side what you see are different microservices within the Dropbox/GDrive service. We have a gateway service, synchronization service, and also have file and folder metadata service. Also, the Customer and devices module is there, and then we have notification and object storage service.
Also, we have chunk service and billing service. I’m not going to detail the design of the gateway service. The Customer and devices store information about the user and all the devices that the user has. The file and folder metadata service stores all the information and all metadata information about a file. And also it also stores the information about if a file is shared with multiple users then that sharing information is also stored in the file metadata service.
Synchronizing service, the changes are stored in the block service and object service and then the file editor service for the file. Whenever a new file gets created the information is stored here in the file metadata service similarly when a file gets shared with another customer/user, then the information gets added to the file folder metadata service. And similarly, for other customer devices if they are running, and are online the synchronizer component in the client app communicates with the synchronization service to receive all the changes that have been done on different files under the user namespace or the shared namespace which the device is subscribed to.
Frequently Asked Questions
The Chunker is a component that is responsible for breaking a file into multiple chunks and it is also responsible for calculating the cryptographic hash for each chunk. You can use any algo like Sha-256 or 512.
Please refer to this complete blog for this answer. You can use java microservices and Load balancing technology to implement this.
The replication consistency is measured when a file/folder update happens on the device, it will take some time to that gets replicated to the file storage service and also to other devices. The higher the replication consistency better the performance.
There are many APIs required according to the design of this service. It is not specific to our choice. In this blog, I have used 6 APIs to handle file sharing, object storage, Synchronization/Metadata, notification and Billing.
There are many services available but very popular are Dropbox and Google Drive and these are highly efficient and cost-effective.
Sync service in the client application is the one that is responsible for syncing all the changes that happen on the device to the remote Dropbox/GDrive service or vice versa. Synchronizer in the client application any changes that happen on a device the synchronizer informs those changes to synchronization service.

Recent Blogs
Categories


