With over 130 million subscribers and a presence in more than 250 countries, System Design for Netflix is a company that manages a large range of movies and television content. Users pay a monthly fee to access this content and what it means for Netflix. The user experience should be very simple and enjoyable.
How does Netflix Operate behind the scene?
Netflix operates in two clouds:
1. AWS.
2. OpenConnect.
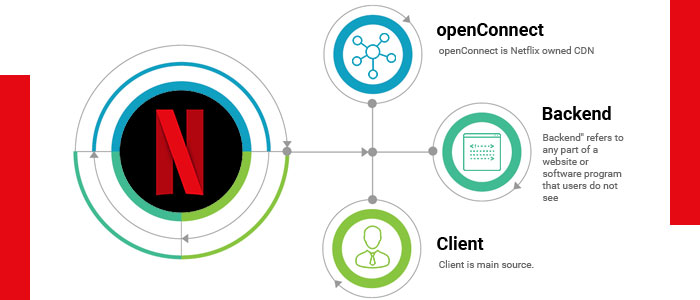
Both clouds must work together seamlessly to deliver endless hours of video for users. Netflix has three main components i.e.:
- OpenConnect
- Backend
- Client
Now Java experts are going to mention some high-level working of Netflix and then jump right into all these three components in depth. Without the knowledge of high-level work, if they go and write the components of system design for Netflix it will be pretty hard for you to understand. So, the Java development team is going to mention a high-level overview of Netflix.
High-Level Overview of Netflix System Design
First, let’s understand what is a client? A client is any device from which you play the video on Netflix it could be your desktop, could be Android, or it could be your iPhone, it could be your Xbox or anything like that.
Another thing is that everything that is not included in video streaming is handled in the AWS cloud. When you hire Java developers for application development, they know everything. Anything that involves video streaming is completely controlled by OpenConnect.
What is open openConnect?
openConnect is a Netflix-owned CDN. Simply put, a CDN is a contingency delivery network, a network of distributed servers placed in different locations or in different countries or locations to serve content more quickly. For example, say you are in India and you have a website that hosts videos on it what if the user is requesting a video hosted on your website from the United States. That means the packets or the video should be traveling from the server in India to the US through C cables, which are used for serving the internet.
Now how do we solve this problem? To solve this problem, what we need to do is let’s have more servers placed in different countries. For example, the main server, which is in India is called the origin or original server. And will have different cache servers that hold all the video copies in different countries. There may be multiple different edge servers that place in North America, South America, one in Russia and one in Europe, and one somewhere in Indonesia. If a user is requesting the video, which is on your website from the United States. The video will be served from, the nearest server that’s the edge server which is in the United States.
This way the content will deliver much faster, and less bandwidth consumed, between India and the United States. Now that you understand what CDN is? OpenConnect is a Netflix-owned CDN. What Netflix has done is they have placed a lot of servers like thousands of servers in every country, so that if the user is requesting a video. Then the video will play from the very nearest server, which places for that particular user.
What is the System Design flow of Netflix?
It’s time to understand the system design for Netflix. As I told you earlier, except for Open Connect, all other components are located in the AWS cloud. Just OpenConnect is a network of distributed servers, maintained by Netflix.
Diagram of System Designing
Now Java professional is going to mention individual components in the system design. The first one is the client.
Client:
Netflix supports a lot of different devices including smart TV, Android, iOS platforms, big gaming consoles, etc. All these apps are written using platform-specific code. Netflix web app is written using react JS, and react.js was influenced by several factors the first is startup speed, the second is a runtime performance of react.js, and the third one is modularity.
Elastic Load balancer
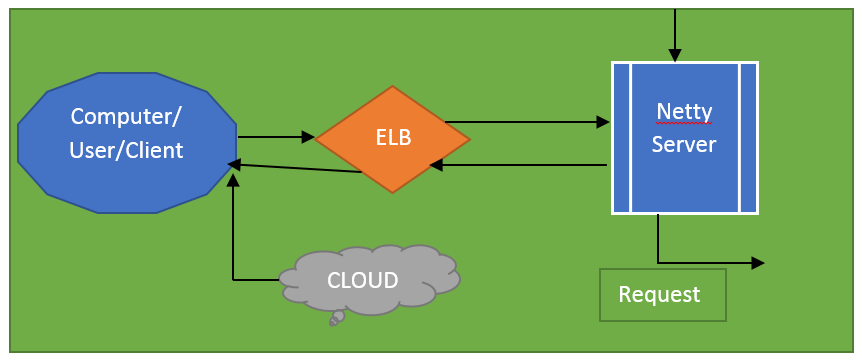
Let me mention elastic load balancers. Netflix uses Amazon’s elastic load balancing service to route the traffic to different front-end services, and these are instances that are an actual response. These are the instances or servers.
Elastic load balance is set up in such a way that the Lord is balanced across the zones first. And then the load is balanced across the instances, and this scheme is called a Two-tire balancing scheme.
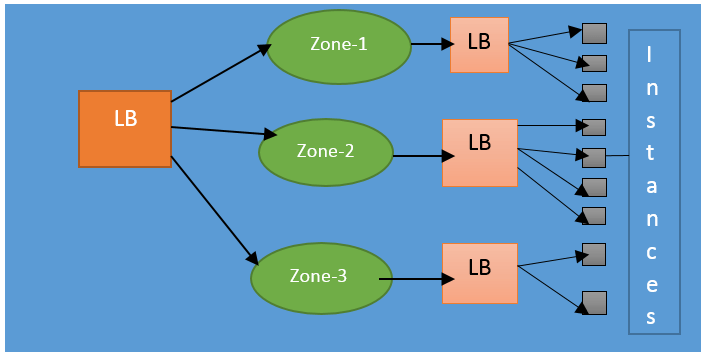
Therefore, this part, which is the first level, involves basic DNS-based round-robin load balancing. Therefore, the first balance in this zone will do using a round-robin when the request lands on this load balancing.
What are zones? Zones are a kind of logical grouping of servers there could be three different zones in the United States itself and one Zone in India. It’s a very logical way of grouping servers together. And the second tier of elastic load-balanced service is an array of load balancer instances. That does round-robin load balancing on the instances to distribute the requests across these instances.
For example, then the request comes in the first level and distributes the load over different zones. And the next level will distribute between these two instances.
How does Netflix Onboard a Video?
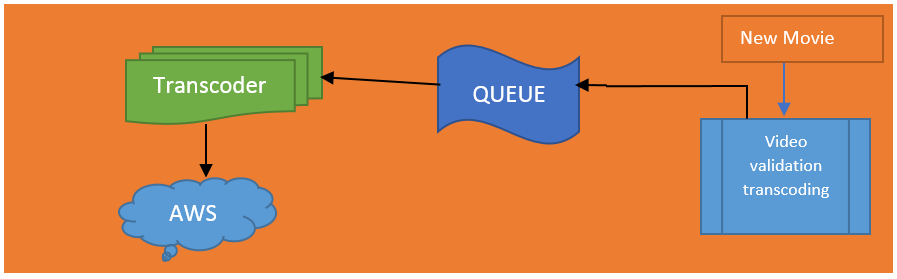
Now let me write about how Netflix is on boards of video. Before a video, web series or movie is made available to the user, what Netflix does is it does do a lot of pre-processing. And this pre-processing involves finding errors and converting the video into different resolutions and a different format. This process calls transcoding.
Transcoding is a process that converts video to a different format and will optimize for this particular type of device. Because you already know that Netflix supports many different types of devices or platforms. So, we have to convert the video to a different resolution to make the viewing experience better.
So, you might ask the question why we don’t just play the video as it is how we get it from the production house. The problem is the original movie, which we get to say for example will be of about many terabytes sometimes. And sometimes it will be of about 50 GB and say a video of about one. And a half-hour movie will be like 50 GB, and this will be pretty hard for Netflix to stream such a big file to every customer. It could be a space constraint; it could be bandwidth.
Adaptive bitrate streaming
Netflix also creates files optimized for different network speeds. For example, if you are watching a movie on you know slow Network, then you might see a movie, that play in very little resolution. If you are watching the same movie on a high-speed network, the movie may be in 4k resolution or 1080p resolution, or sometimes when the bandwidth is low, the movie suddenly changes resolution. You may have observed a granular type resolution sometimes like a sudden high-definition resolution. And this type of switching is called adaptive bitrate streaming.
To do that, Netflix has to make multiple copies of the same movie in almost different resolutions. Netflix makes about twenty thousand different copies for a single movie just to do that, and if it has to process a lot of files, then how does Netflix do it? Netflix uses many different parallel workers to do what it does.
So when they want to onboard a particular movie, they get the movie as a single file, which about says 50 GB. And then what they do is they break that moving to a lot of different pieces or chunks you can say and put it all into the queue. And then these tasks or these individual tasks, which are to process for each clip will be placed in the queue. And then these tasks will pick up by the different workers, and they all process different chunks together. And then they merge all these videos or they place the different clips and upload the clips into Amazon s3.
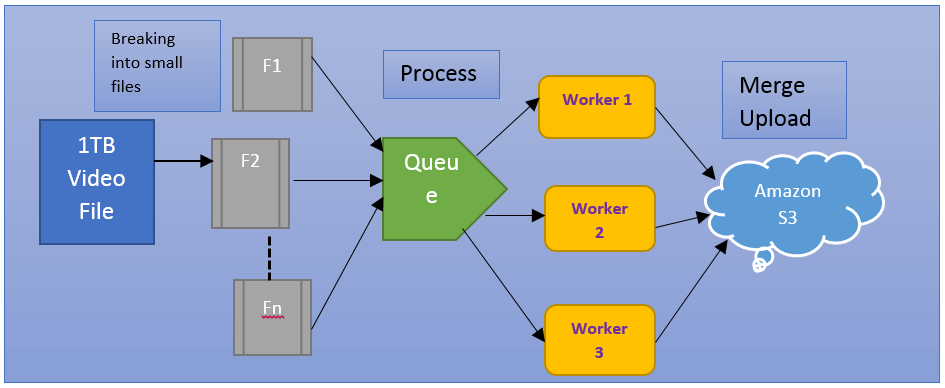
Now that our Amazon ec2 workers have converted the source movie to different copies of the movie of different resolutions and different formats. We have about 1200 copies of different files for the same movie. Now it’s time to push all of these movies into openConnect distributed servers, which place in different locations across the world.
That means all these different copies will push to every server in the openConnect Network. So, here is what happens next? When the user loads the next Netflix app on his mobile phone or smart TV or web app, what happens is all the requests like login, recommendation, homepage, search, billing or customer support, etc.
All these kinds of different requests handle by the instances which are in the AWS cloud. And the moment you found to find the video, which you want to watch and hit the play button on the player, what happens is the application will figure out the best open connect server. And the open connect server will start streaming the video to the client/user.
The client is so smart that even when the OpenConnect server is streaming video. These apps will constantly check for the best OpenConnect server. That is available near that particular application, and it switches dynamically depending on the bandwidth quality on the server. And load on OpenConnect server.
It is how the Netflix application gives the best viewing experience to the user without any obstruction or interruption while you are watching the video. With the information like whatever you searched, whatever you typed, and your video viewing pattern, all this information will save in data centers in AWS. And Netflix does create machine learning models using that data to understand the user choices better. And to build the recommendation engine.
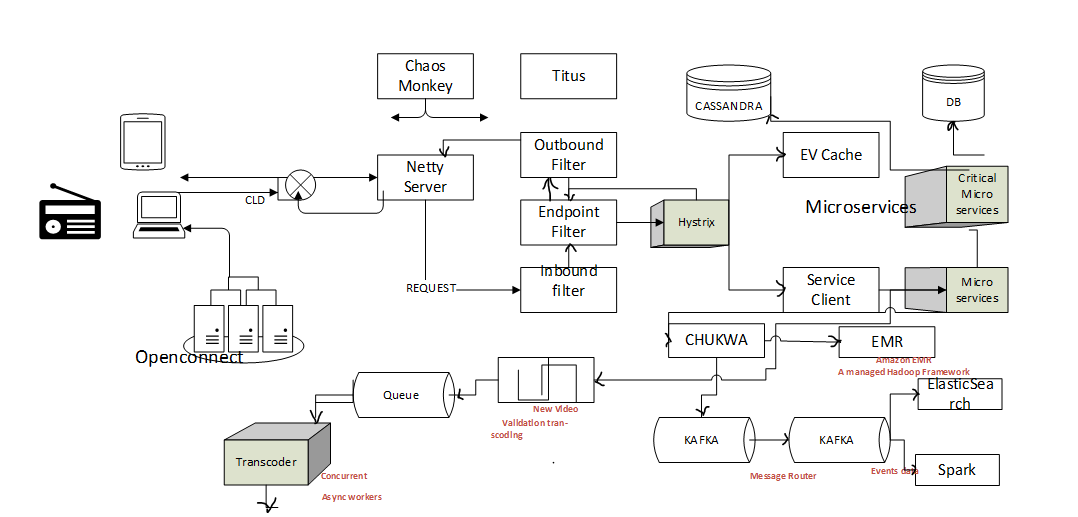
Zuul
Now let’s learn about the next component called Zuul
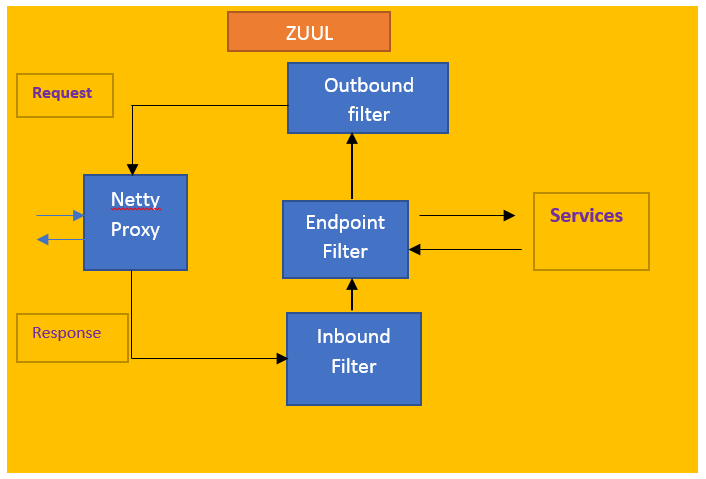
Zuul is a gateway service that provides dynamic routing, monitoring resiliency, and security. The whole service can also use to do connection management and proxying the requests. So, the main component over here is the Netty server-based proxy. And this is where the requests will hit first, and then this will be proxying the request to the inbound filters over here.
The inbound filter run before proxying the requests and can use for authentication, routing, or decorating the requests. And the request goes next to the endpoint filter. The endpoint filters can use to return the static response or to forward the request to back-end services. Once the backend service returns feedback, the inbound filter will transfer that responsibility to outbound filters. And after seeing the response, outbound filters can use to zip up content to calculate metrics or to add or remove headers from Response.
Once the response is written back to the Netty server, it will send back the response to the client. Now, what are the advantages of having a gateway service like this in the above diagram? See the advantages are many more. The first thing is you can share the traffic? For example, you can have a web-tier rule somewhere that sends some traffic towards these servers and send some traffics to these kinds of servers of saying different versions. For example, you can share the traffic by having the rules set in the endpoint filter, and also you can do some kind of load testing.
Let’s say you have a new kind of server that deploy in certain setups of the machine and you want to do load testing on it. In that case, also you can redirect a part of traffic to that particular set of services. And then see what load that particular service our server can take. The third one is you can test new services.
When you upgrade the services, maybe you want to test how it behaves with the real-time API requests, instead of replacing them or deploying in deploying the new service on all of the servers. What you can do is, you can deploy that particular new service or upgraded service onto one server. And then you can redirect some parts of traffic or some percentage of traffic to that new service, and then test that service in real-time.
Also, you can filter the bad requests. You can have custom rules set in the endpoint to filter the responses based on certain conditions say a user agent of a specific kind. Then filter all the requests, you can either have it in the endpoint filter, or you can have it in the firewall.
Hystrix
Let’s see what Hystrix is. It is a latency and fault-tolerant library design to isolate the points of access to the remote system, services, and third-party libraries. What that means is to say, for example, you have an endpoint “A” from which the request and response deliver. So in micro-service architecture, this endpoint might be requesting a lot of different other microservices that are in different systems altogether.
For example, there can be multiple servers, and this could be a different server, or this could be another third-party service called. And there could be another machine this too could mean a different machine. Because one particular call is slow, your whole endpoint might suffer a lot of latency i.e. the time to deliver the response might take more time. Or maybe one service is down, and that’s the reason why the errors will cascade. If one microservice call is causing some error, then this error will cascade back to the endpoint, and this response could respond response with an error.
So, these kinds of problems we can control using Hystrix, which helps stop cascading failures and also do real-time monitoring. What are the advantages of Hystrix? So here, hire backend developers have listed out a few advantages of using Hystrix. When you are configuring your Hystrix, Hystrix will take care of every microservices.
It means that you are decorating each microservice, and how it helps, for example, you want to keep the quality of your service. At a certain endpoint for a maximum of 1 second or two seconds, which means you have a timeout for each microservice Should also be set. It means that the first advantage is that you can kindly delete a call to that particular microservice if the response time is longer than the current time, or maybe it will refund if you are configured to respond by default.
The second advantage is the thread pool for a particular microservices is full, it won’t even try to accept the next request. And keep waiting for that it’ll just straight up and reject the call so that the other microservice handles it there. And continue forward or do whatever the mitigation it wants to do or it could fall back to the default response. In the same case, the third point is that, it can do the same thing as not responding to the default or if the error rate is higher than, the percentage of errors, not taking down the microservice. And the fourth issue is returning to the default response because I already mentioned it.
The fifth one is it will be much useful to collect the metrics to understand how these microservices are performing so. Hystrix gathers the data about the latency, the performance, and everything. And puts it in a dashboard so that you can understand what the businesses are performing and how better.
Netflix uses microservice architecture to power all of its API needs to applications. And perhaps the request calls to any endpoint go to another service, and it keeps on happening. In the next advanced blog on Netflix system designing, Java programmers have mentioned advanced features like caching, Logging, Database design, etc. Please refer to all of our system designing blogs to understand more about a specific product.

Recent Blogs
Categories


