In this article, we will check out how to make the process run parallel in Python. And also, we will learn what concurrent.futures is, How to fetch data from URL, etc. By default, the program uses a single core of the CPU, as in Python. So, by making the program run parallel, we will use multiple cores of the CPU. I have two cores in my system. You may have 4 or more. Using multiple cores of the CPU will result in an increased speed of execution. So, let’s start.
Let’s learn how to take advantage of a whole lot of CPU cores or processing power of your system by running your program in parallel. It is a module of Python which will convert the normal program into parallel code with changes in 2-3 lines of code. Though there are some other ways also to run parallel, this is one of the good ways to do this, such as we can use the multithreading and multiprocessing module of Python as well. Now let’s look at concurrent.futures module of Python.
What is concurrent.futures?
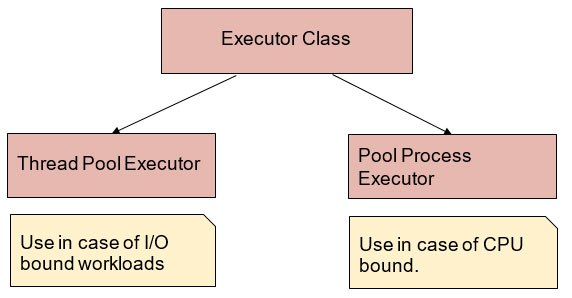
It is the standard module of Python, and it helps in achieving asynchronous execution of the Program. This module is available in Python 3.0+ providing a high-level interface for the asynchronous task. It can either be performed with threads using ThreadPoolExecutor or segregate processes using ProcessPoolExecutor. These are both defined under the Executor Class of this module.
What is the Executor class?
It is the abstract class of concurrent.futures module. It can be used directly and will use with its subclasses, and they are as follows:
- ThreadPoolExecutor
- ProcessPoolExecutor
For more information about this module, please refer to https://docs.python.org/3/library/concurrent.futures.html
Python is a good programming language for repetitive tasks or automation. But it will be slow if you want to assume processing a large amount of data or fetch data from URL etc. Suppose you want to process a hell lot of images, and if will use parallel processing, it will reduce computation time. Here this tutorial will discuss examples of fetching data using URL.
Fetching data from URL
Normal Approach
So, here we are fetching data/Html code of the following URLs for any reason supposed to want to scrape data from websites. It can be one of the major applications in data science as well. Because many times there is a need to fetch data from websites.
If we will run this program without parallel implementation, it will take so long. In my case Output is
Output(Normal Approach) -: Time taken to fetch data is 69.38949847221375 secs
Let’s see what the difference will be if will use a parallel approach.
Output (Pooled Approach) -: Time taken to fetch data is 19.51672649383545 secs
So, if we will check the difference, it is three times faster. There we are taking less data, but in real use cases, there may be thousands of URLs or more than 10k images to a process where you will really find this approach useful.
Will it always boost up speed?
Generally, it is noticed that this parallel execution is really helping in boosting the speed of a certain program. But for sure! There may be the case that it will fail. As such, if we have independent processes, then we can make use of ProcessPoolExecutor, and it will be useful when CPU bound is there, and ThreadPoolExecutor will be useful when I/O bound is there.
As in Python Django development concept of “Global Interpreter lock” (GIL) is also there. Hence keeping that concept in mind will make better use of Pool Executor. If you want to harness the full potential of Python Django and make the most out of Pool Executor, partnering with a reliable Python Django development company can provide you with the expertise and experience needed to create high-performance web applications.
I hope this gives you a clear idea of Pool Executor and how to use it practically.
Applications for parallel/asynchronous processing:
- Parsing data from CSV, Excel, URL
- Processing whole bunch of images for Image Processing
Conclusion
In this blog, we have seen with the help of concurrent.futures module of Python, how to run program parallel and helps in boosting up the speed. We have also explained the usage of this module with the help of some examples. In many applications, this parallel processing is really helpful. The more times your CPU is idle, you can make it run faster by using multiple cores of the CPU.



