Once we have developed the Pentaho ETL job to perform certain objective as per the business requirement suggested, it needs to be run in order to populate fact tables or business reports. If we are having job holding couple of transformations and not very complex requirement it can be run manually with the help of PDI framework itself.
While dealing with real-time Pentaho ETL jobs consisting of a large number of jobs and transformations and lots of parallel and sequential job processing involved, running this kind of job from the PDI framework locally is not a reliable method as it is an error prone. As the job runs on the PDI framework it is running on a local machine that is intended to fail due to physical or network problems.
Another thing is that a real-time production level job requires lots of computational power and network bandwidth which local systems are unable to provide and we need to host these jobs on production servers satisfying all the computational requirements.
So once the jobs are deployed on production servers, they need to be run as per schedule or manually. Every complex Data Warehouse system has a requirement to run those jobs at a certain fixed schedule as most jobs are dependent on each other.
Scheduling is just one aspect of running ETL tasks in a production environment. Additional measures must be taken to allow system administrators to quickly verify and, if necessary, diagnose and repair the data integration process. For example, there must be some form of notification to confirm whether automated execution has taken place. In addition, data must be gathered to measure how well the processes are executed. We refer to these activities as monitoring.
In this Pentaho Data Integration tutorial, we take a closer look at the tools and techniques to run Pentaho Kettle jobs and transformations in a production environment. There are lots of methods through which we can schedule the PDI jobs.
You can schedule your jobs through:
- Data Integration (DI) Server
- Manual scripting through pan or kitchen commands
i. Data Integration (DI) Server
This method is done through the Spoon graphical interface & is only available for the Enterprise repository. After you design your job, the steps are as follows:
Enter your configurations in the Schedule a Transformation dialog box.
Open your particular job or transformation which needs to be scheduled.
Then go to the Action menu and select Schedule.
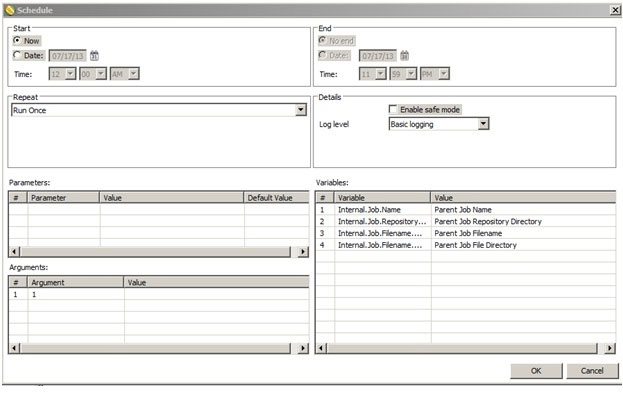
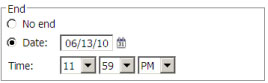
For the Start option, select the Date, click on the calendar icon. Choose the required date and Click Ok. For the End date, select Date and then enter a date till which job will be scheduled.
Select the frequency at which the job needs to be executed. Under the Repeat section, for instance, select the Weekly option.

In order to modify the schedule click on the Schedule perspective on the main toolbar. It shows previous and next schedule information along with duration and who scheduled it too.
ii. Manual scripting through pan or kitchen commands
A Most common method of scheduling on Linux machines is by using the CRONTAB scheduler. It is the easiest way to schedule a command on a Linux machine.

In order to run the job, we need to create a shell script which will contain job path details from which the job will be executed. Next, we need to schedule this script to run at a particular schedule.
We need to follow these steps to schedule job:
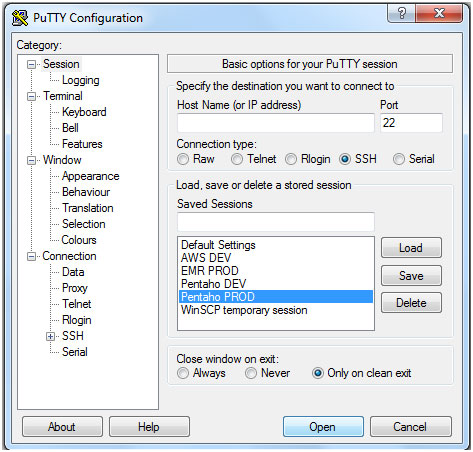
- If we are scheduling from Windows OS, Open PuttY.
- Login
- Authentication
- Type following command on shell to long list the scheduled crontabs.
crontab–l
This will give all the list of scheduled jobs intended to run at a particular scheduled time.
The Cron time string format consists of five fields that Cron converts into a time interval. Cron then uses this interval to determine how often to run an associated command on your production server.
For example, a Cron time string of the following format executes a command on the 15th of each month at 10:00 A.M. CST.
0 10 15 * *
These are convention it follows-
Formatting-
The Cron time string is five values separated by spaces, based on the following information:

The Cron time string must contain entries for each character attribute. If you want to set a value using only minutes, you must have asterisk characters for the other four attributes that you're not configuring (hour, day of the month, month, and day of the week).
Note that entering a value for a character attribute configures a task to run at a regular time. Even if you add a slash (/) and an integer to the wildcard in any position of the letter, you still get regular time (for example, every X minutes/hours/days). Here are a few examples of scheduling-

Here each job is having a bash script with their complete path on Pentaho Server (Linux Machine)-
Login to Production server via PuttY-
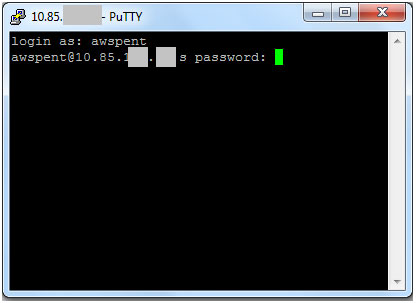
Enter Credentials of AWS Linux Machine-
Here is landing screen-
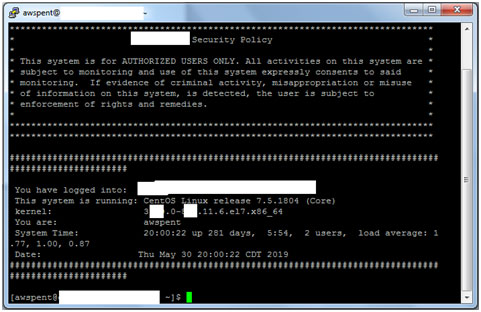
Type crontab -l for long listing of all scheduled jobs-
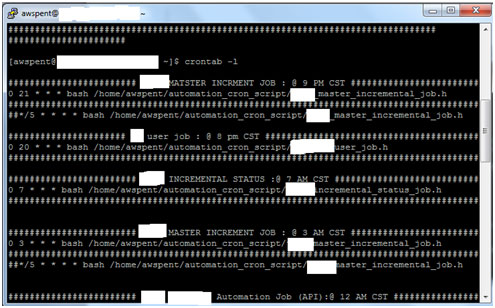
Here each of job is having bash script with their complete path on Pentaho Server (Linux Machine)-
/home/awspent/automation_cron_script/Job_header_filename.h
This Job_header_filename.h contains a script consisting of the name of the job that needs to be executed and the relative path of the same. It consists of the nohup command which will be using Kitchen.sh file for running jobs.
Below is screenshot of file system location for Job_header_filename.h
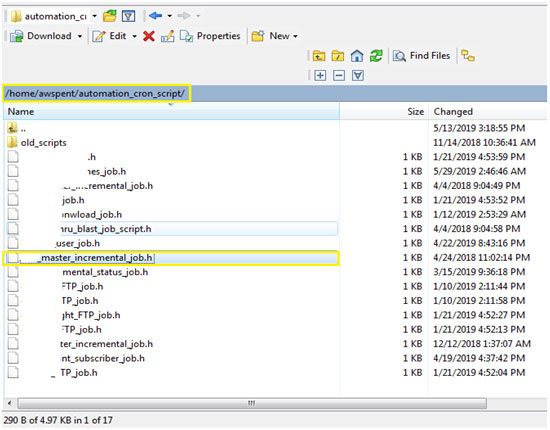
Each of .h extension file has the following script for running the specified job.
master_incremental_job.h
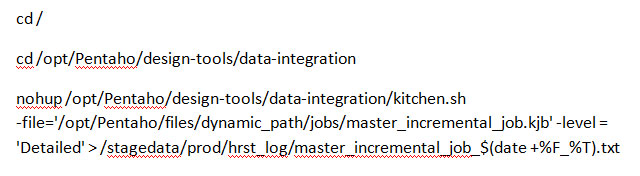
-file = Path of job needs to be executed.
-level = Level of log details which will be written in log file.
/stagedata/prod/hrst_log= Path at which log needs to be written along with extension.
Here are two jobs which will run at 9 PM CST time.
Second job is prefixed by ##which means job scheduling is disabled. It won’t run for next coming time schedule.
To make changes to the schedule we need to execute the following command-
crontab - e
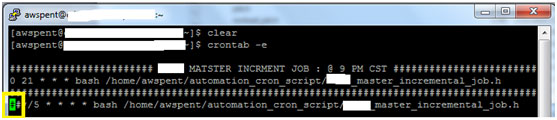
This will allow us to edit crontabs.
Conclusion:
In conclusion, we can use the first method i.e. DI server for small utility jobs, and the crontab method for complex real-time production jobs.
Depending upon the system we can use any of the methods suggested above, most commonly used scheduling method is using Crontab scheduler with a shell script which provides lots of customization for a running job at a predefined time slot.



