
Are you a machine learning enthusiast? Or a freaking nerd who is always concerned about time and space optimization in your code? Well, anyway, it’s a blog for making developers wiser during coding.
INTRODUCTION
With the advancement of the AI era, many new machine learning algorithms and optimization techniques do invent to cut a throat for the best time and space complexity. Keeping this in mind, let me introduce a not very old yet very powerful Python library, Joblib. Joblib brought a breakthrough in various contexts of Python activities such as loading up large Numpy arrays, serializing and persisting python object or performance of python functions you build, seeking with the help of parallel computing, memorization (not typo mistake,’r’ doesn’t exist) and caching mechanism in addition to multi-processing, loky(default) and threading backend.
This blog will give you shivers and shrieks when you will be awed by the performance of Joblib. Let’s cut to the chase. We will be crossing the following milestones.
Dive into Joblib
Features which made Joblib an Avenger
How to get started?
Main Conceptual Features of Joblib
Joblib functional areas of optimization in Python
Implementations of Joblib
DIVE INTO Joblib
Joblib does a library built purely in Python by sci-kit-learn developers. It entirely focuses on optimizing python-based persistence and functions. An awesome library that has become popular due to its optimized time-complexity feature, especially for handling big data. It provides lightweight pipelining in Python development services.
Problem: Many challenges we face while dealing with large data. Call it taking huge time and space when working with intensive computational functions or persisting then loading huge data as a pickle.
Solution: Joblib
Features that made Joblib an Avenger in reducing time complexity:
- 1. Fast Disk-caching and lazy-evaluation using hashing technique as well
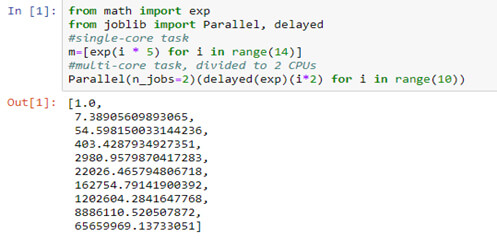
- 2. Capable of distributing jobs (parallelization) using a Parallel helper
- 3. Compression feature during persistence containing large data
- 4. Best known for handling large data
- 5. Specific optimization for handling large Numpy arrays
- 6. Memoization where function called with same argument won’t re-compute, instead, output loads back from cache using memmapping Cherry on the cake
- 7. No dependent library (except Python itself)
Later, we will look over the practical examples of the above features one by one. Stay tuned!
How to get started?
You can install Joblib using pip as follows:
Main Conceptual Features of Joblib
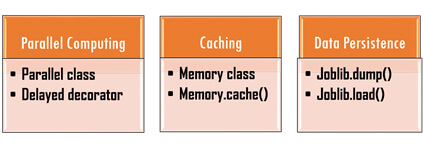
Parallel Computing:
1. Parallel class
Normally, concurrent computing achieves by the n_jobs argument referring to different concurrent processes which means OS lets those jobs run at the same time. Generally, it refers to CPU (processor) cores whose value does determine by a task. Suppose a task of intensive I/O but not with a processor, then processes can be more.
Also, you can explore more about “backend” which gives you options like multi-processing and multi-threading. For more info, check out the documentation.
2. A delayed decorator
A delayed is a decorator mainly to get the arguments of a function by creating a tuple with function call syntax.
Caching (Memoization)
1. Memory class
Lazy evaluation of Python function in simple terms means a code though assign to a variable that will execute only when its result does need by other computations. Caching the result of a function is termed memorization to avoid recomputing.
Also avoids rerunning the function with the same args. Memory class stores result in a disk that loads back the output cache by using hashing technique when a function does call with the same args. Hashing will check out whether output for inputs does already compute or not, if not then recomputed or else loads cache value. It is mainly a feature for large NumPy arrays.
Output is saved in a pickle file in the cache directory.
2. Memory.cache()
Callable object furnishing a function for stashing its return value each time it is called.
Data Persistence
Joblib offers help in persisting any data structure or your machine learning model. It has proved to be a better replacement for Python’s standard library, Pickle. Unlike the Pickle library, Joblib can pickle Python objects and filenames.
Breakthrough is optimizing space complexity during pickling which is achieved by joblib’s compression techniques to save a persisted object in compressed form. Joblib compresses data before saving it into a disk. Various compression extensions like gz, z, etc have their respective compression methods. For more info, visit the following link. http://gael-varoquaux.info/programming/new_low-overhead_persistence_in_joblib_for_big_data.html
Joblib AREAS OF OPTIMIZATION IN Python
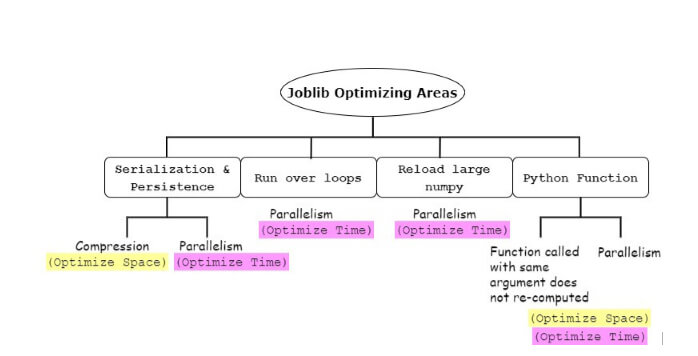
IMPLEMENTATIONS of Joblib
1. Run over loops (Embarrassingly parallel for loops)
2. Reload large numpy (Memoize pattern)
As mentioned previously, memorize refers to just loading up the output from the cache for the function called with the same arguments again.
Memory class context is also used over NumPy when it comes to the long calculation of NumPy or loading large NumPy. This can be achieved using mmap_mode (memory map) or just the decorator function.
Using Memmapping (memory mapping) mode is helpful while reloading large NumPy arrays by speeding up the cache to find out. Can also use memory.cache decorator.
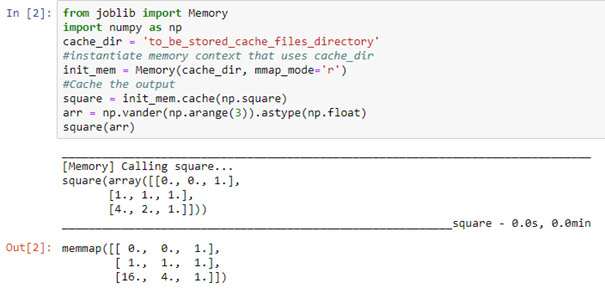
The Square function is called again with the same argument which is now using memorize technique using mmap_mode (Memory mapping) which again uses hashing technique so as to speed up the cache.
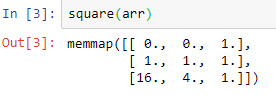
Using the decorator function, here fun1 does call again with the same arguments and will follow a memorized pattern.

3. Python function (Memorize (caching) +Parallelism)
Caching: While working with the custom python function as demonstrated below, it took 5.01 s.
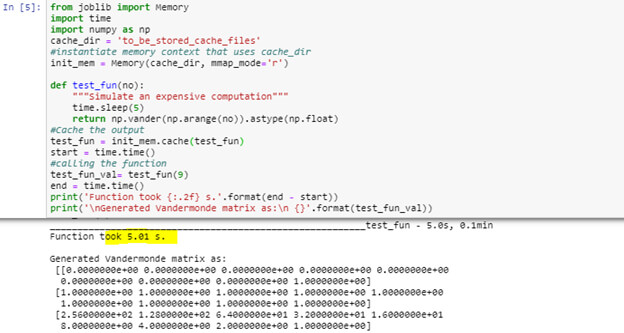
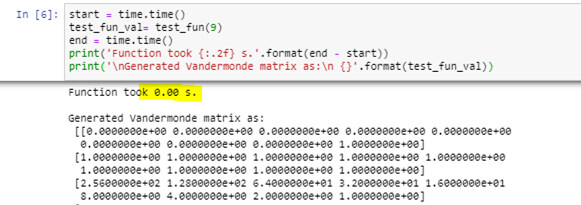
The same function when called again takes 0 s since to load output from the cache.
4. Serialization and Persistence
With Joblib you can persist filenames or even file objects. Python objects can be any data structure object or even your machine or deep learning model. Let’s look at the ways to dump and load objects.
- Normal persisting and loading of list object

Persisting file does compress using compress argument, hence achieving space-complexity will indirectly effecting time-complexity during loading up of the object.

- In below example, ‘.z’ compressed file is dumped.

- In below example, .gz compressed file is dumped which has gzip compression method with compression level of 3.

- As you can see below, difference of storage between varied forms of pickle files.

CONCLUSION
Every beginning has an end. Well, that’s a cycle of nature! Likewise, our blog came to an end. We have seen how Joblib is a life savior in the context of handling huge data which could have taken a lot of space and time, if not without Joblib. The blog has immensely described this lightweight pipelining library which is capable enough to optimize time and space. Features like parallelism, memorization, and caching or file compression outperformed all ML/AI libraries.
In machine learning, a huge model pickle file now can no more consume a lot of space and load the same file more quickly. But, life isn’t fair every time, right? Jokes apart!
Joblib can at times not be quicker when a small amount of data comes into view. But, above all, it is recommended over the Pickle library for object persistence and can be considered when in need to perform Parallel tasks.



