
In Machine Learning, many of us come across problems like anomaly detection in which classes are highly imbalanced. For binary classification (0 and 1 class) more than 85% of data points belong to either class. So, this blog will cover techniques to handle highly imbalanced data. Here, some of the classic examples are fraud detection, anomaly detection, etc.
Let’s dive into the details of these techniques.
These techniques are given by a leading Python Django development company.
List of techniques -:
- Random Undersamopling
- Random Oversampling
- Python imblearn Undersampling
- Python imblearn Oversampling
- Oversampling : SMOTE(Synthetic Minority Oversampling Technique)
- Undersampling: Tomek Links
Looking at imbalanced data
Here, I have collected raw data from here:
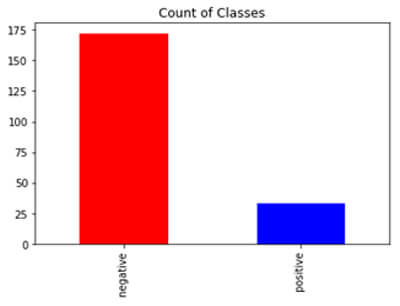
Data is about the classification of glass. It has 2 imbalanced classes, here it is not highly imbalanced but they are imbalanced. Let’s take a look with the help of code.
| RI_real | Na_real | Mg_real | Al_real | Si_real | K_real | Ca_real | Ba_real | Fe_real | Class | |
| 0 | 1.515888 | 12.87795 | 3.43036 | 1.40066 | 73.2820 | 0.68931 | 8.04468 | 0.00000 | 0.1224 | negative |
| 1 | 1.517642 | 12.97770 | 3.53812 | 1.21127 | 73.0020 | 0.65205 | 8.52888 | 0.00000 | 0.0000 | negative |
| 2 | 1.522130 | 14.20795 | 3.82099 | 0.46976 | 71.7700 | 0.11178 | 9.57260 | 0.00000 | 0.0000 | negative |
| 3 | 1.522221 | 13.21045 | 3.77160 | 0.79076 | 71.9884 | 0.13041 | 10.24520 | 0.00000 | 0.0000 | negative |
| 4 | 1.517551 | 13.39000 | 3.65935 | 1.18880 | 72.7892 | 0.57132 | 8.27064 | 0.00000 | 0.0561 | negative |
| 5 | 1.520991 | 13.68925 | 3.59200 | 1.12139 | 71.9604 | 0.08694 | 9.40044 | 0.00000 | 0.0000 | negative |
| 6 | 1.517551 | 13.15060 | 3.60996 | 1.05077 | 73.2372 | 0.57132 | 8.23836 | 0.00000 | 0.0000 | negative |
| 7 | 1.519100 | 13.90205 | 3.73119 | 1.17917 | 72.1228 | 0.06210 | 8.89472 | 0.00000 | 0.0000 | negative |
| 8 | 1.517938 | 13.21045 | 3.47975 | 1.41029 | 72.6380 | 0.58995 | 8.43204 | 0.00000 | 0.0000 | negative |
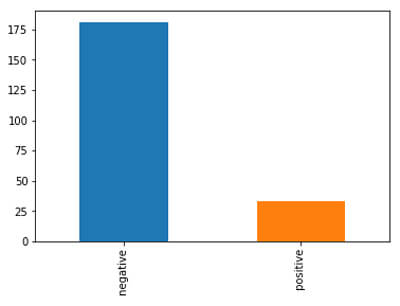
So, here positive class covers about 15% of data which is an imbalance in nature
Now, let’s start looking at techniques to handle this problem.
Random Undersampling
In this, what will happen is the majority of class examples will be sampledi.e., some of the examples which belong to the majority class will be removed. It has advantages but, it may cause a lot of information loss in some cases. Let’s look at code, and how to perform undersampling in Python Django development.
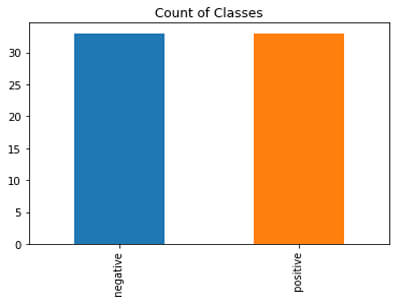
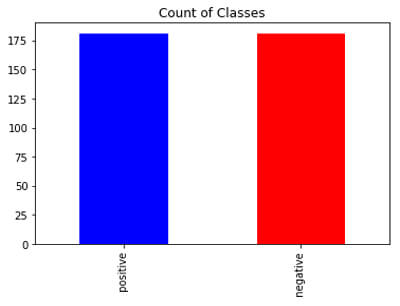
After undersampling, we have 33 data points in each class.
Here undersampling is not a better option because we already have 200 points and after that, we reducing just to 30’s which is less. So, it depends upon the use-case as well.
Random Oversampling
Random oversampling will create duplicates of randomly selected examples in the minority class.
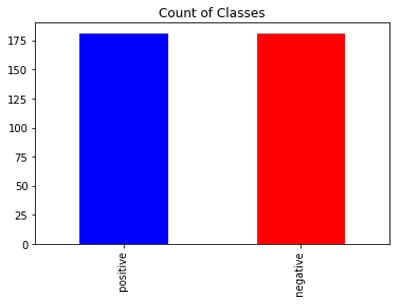
Undersampling using Imblearn
Let’s look at undersampling using imblearn package in Python.
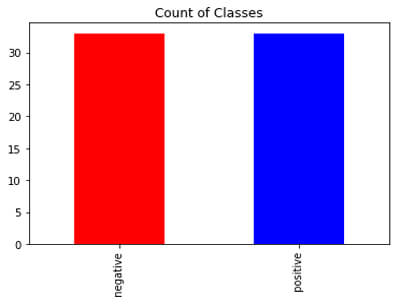
Similarly, we can perform oversampling using Imblearn. It might confuse you why to use different libraries for performing undersampling and oversampling. Sometimes, it happens that undersampling(oversampling) using imblearn and simple resampling produces different results and we can select based on the performance as well.
Tomek links
Tomek links is the algorithm based on the distance criteria, instead of removing the data points randomly. It uses distance metrics to remove the points from the majority class. It finds the pair of points that has less distance between them one from the minority class and another from the majority class and will remove the majority point from that pair.
SMOTE
It stands from the synthetic minority oversampling technique. It also performs oversampling.
Conclusion
Hope you are clear with different techniques to overcome with imbalanced dataset in Machine Learning. There are many other methods to deal with imbalance thing. It depends upon your dataset when to perform oversampling and when to perform undersampling. If your dataset is huge then go for undersampling otherwise perform oversampling or TomekLinks.
Hope you enjoyed learning. Keep learning with new stuff in Machine Learning.



