Introduction to HDFS
Hadoop Distributed File System (HDFS) is the first and the essential concept of Hadoop. It is a Java-based distributed file system. The design of HDFS is based on the Google file system and is used to store a large amount of data on clusters of commodity hardware. It is also known as the storage layer of Hadoop.
Features of HDFS:
Reliability
Hadoop file system provides data storage that is highly reliable. It can save up to 100s of petabytes of data. And it stores data in blocks that are further stored in racks on nodes in clusters. It can have up to N number of clusters, and so data is reliably stored in the blocks. Replicas of these blocks are also created in the clusters in different machines in case of fault tolerance. Hence, data is quickly available to users without any loss.
Fault Tolerance
Fault Tolerance is how the system handles all unfavorable situations. Hadoop File System is highly tolerant as it follows the block theory for better configuration. The data in HDFS are divided into blocks, and multiple copies of the blocks are created on different machines. This replication is configurable and is done to avoid the loss of data. If one block in a cluster goes down, the client can access the data from another machine having a copy of the data node.
HDFS has different racks on which replicas of blocks of data are created, so in case a machine fails user can access data from different racks present in another slave.
High Availability
Hadoop file system has high availability. The block architecture is to provide large availability of data. Block replications provide data availability when a machine fails. Whenever a client wants to access the data, they can easily get the information from the nearest node present in the cluster. During the time of machine failure, we can access data from the replicated blocks present in another rack in another salve of the cluster.
Replication
This feature is the unique and essential feature of the Hadoop file system. This feature helps to resolve data loss issues that occur due to hardware failure, crashing of nodes, etc. HDFS keeps creating replicas on different machines in blocks in different clusters and regularly maintains the replications. The default replication factor is three i.e. there are three copies of blocks in one cluster.
Scalability
The Hadoop file system is highly scalable, and this is why Python Web Development Company prefers this. The requirement increases as we scale the data. And hence, the resources also increase, such as CPU, Memory, Disk, etc. In the cluster. When data is high, the number of machines also increases in the cluster.
Distributed Storage
HDFS is a distributed file system. It stores files in the form of blocks of fixed sizes, and it stores these blocks across clusters of several machines. HDFS follows a Master-Slave architecture in which the slave nodes (also called the Data Nodes) form the cluster managed by the master node (also called the Name Node).
Architecture of HDFS
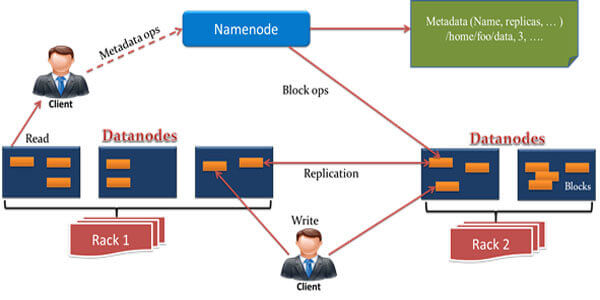
As mentioned earlier, HDFS follows a Master-Slave architecture in which the Master node is called the Name Node, and the Slave node is called as Data Node. Name Node and Data Node(s) are the building blocks of HDFS.
There is an exclusive one Name Node and a number of Data Nodes. The Data Nodes contain the blocks of files in a distributed manner. Name node has the responsibility of managing the blocks of files and allocation/deallocation of memory for the file blocks.
Master/Name Node
The Name node stores the metadata of the whole file system, which contains information about where each block of the file and its replica is stored, the number of blocks of data, the access rights for different users of the file system for a particular file, date of creation, date of modification, etc. All the Data nodes send a Heartbeat message to the Name node at a fixed interval to indicate that they are alive. Also, it sends a block report to the Name node, which contains all the information about the file blocks on that particular Data node.
There are 2 files associated with the Name node:
- FsImage: It stores the image/state of the name node since the starting of the service
- EditLogs: It stores all the current changes made to the file system along with the file, block, and data node on which the file block is stored.
- The Name node is also responsible for maintaining the replication factor of the block of files. Also, in case a data node fails, the Name node removes it from the cluster, handles the reallocation of resources, and redirects the traffic to another data node.
Slave/Data Node
The data node stores the data in the form of blocks of files. All the read-write operations on files are performed on the data nodes and managed by the name node. All the data nodes send a heartbeat message to the name node to indicate their health. The default interval for that is 3 seconds, but it can be modifiable according to the need.
HDFS Commands
Give below are the basic HDFS commands:
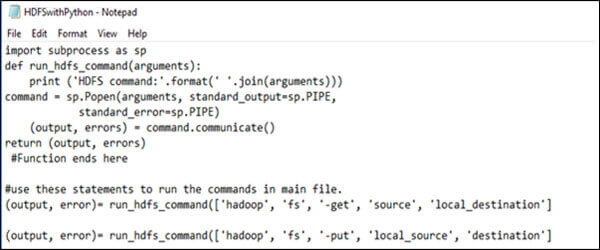
HDFS get command This command is used to retrieve data from the Hadoop file system to local file system.
Syntax: hdfs dfs -get <source > <local_destination>
Example: hdfs dfs -get /users/temp/file.txt This PC/Desktop/
HDFS put command This command is used to move data to the Hadoop file system.
Syntax: hdfs dfs -put <local source > <destination>
Example: hdfs dfs -put /users/temp/file.txt This PC/Desktop/
HDFS ls command This command is used to list the contents of the present working directory.
Syntax: hdfs dfs -ls
Example: hdfs dfs -ls
HDFS mkdir command This command is used to build a latest directory.
Syntax: hdfs dfs —mkdir /directory_nam
Example: hdfs dfs —mkdir /my_new_directory
HDFS du command This command is used to check the file size.
Syntax: hdfs dfs —du —s /path/to/file
Example: hdfs dfs -du /my_new_directory/small_file
There are many more commands in HDFS. Given above are just the basic ones.
Running HDFS commands using Python development