Vert.x is a toolkit for developing reactive applications on the JVM and what do you mean by this is that it is a complete environment for building lightweight reactive applications so you can use it together with Java Enterprise or with Spring Framework but the intention is that Java development services provider use it separately from other big frameworks that dictate how your architecture looks.
Fundamental/Predominant Features of Vert.x:
- Runnable Jar
- Reactive
- Scalable
- Distributed
- Polyglot
If you build a vert.x application you're building a runnable jar with all the dependencies in it and one of the driving forces behind the development of the vert.x.
Building High Performance Lightweight Reactive Java applications with Vert.x
Vert.x project was the reactive manifesto. If you go to the reactive manifesto website, they say that directive manifesto is an answer to the requirements we see for our software. So requirements around a lot of data you always want to be able to access their information, distributed systems and they say there are four traits that you need to have in your application in your architecture to be able to call it a reactive system.
- 1. Elasticity
- 2. Responsive
- 3. Resilient
- 4. Message-Driven
Those are elasticity so it has to be elastic so you should be able to scale up and down modules in your system. It has to be responsive so you should always get feedback even if there are failures so it should also be resilient so if certain modules fail you should still be able to use part of the application and it should be message-driven. So, asynchronous messages are used for communication.
VERT.X Capabilities with Java Microservices:
So, if you look into how vert.x is built and how you build applications with vert.x then you recognize all these traits. Another interesting thing about vert.x is that it uses multiple languages so they have an API to use the utilities inside vert.x and they start with a Java implementation and based on the Java implementation, they generate APIs for other languages, so you can use a Groovy, Ruby, JavaScript, Scala, Kotlin and this makes it versatile if you have a development environment and people are not a Java person by default or they want to use another language to develop their functionality.
Vert.x Distributed Nature:
And finally, the last one is distributed, and I will go into detail a little bit more with that one. So, the intention is to use it separately as a complete solution for your application and it also means that the technology stack includes all kinds of functionality.
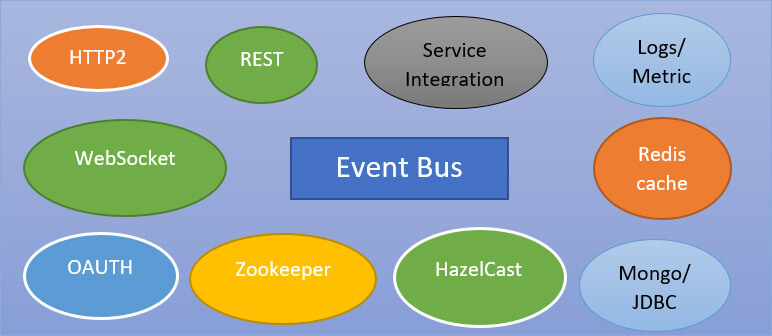
So, you can build rest services there are adapters to use different data sources like MongoDB or Redis but also legacy JDBC drivers. There is also a lot of integration stuff, a lot of protocol supported, and their solutions for metrics and actually, they use the dropwizard metrics and their Integrations with stuff like zookeeper, Hazelcast and Kubernetes.
Asynchronous Programming with Vert.x
If you think about asynchronous applications, they should always be asynchronous front to back. So, from the click in the browser to your data store or your file system, everything should be asynchronous.
So most of the project, you will find asynchronous OJDBC driver that means you can fire a query and do something else in the meantime, when the research comes back it is processed so your threat doesn't block on the query, but it's free to do other stuff. The same goes for MongoDB but which already has an asynchronous java driver but also for calling other web services for writing files to the file system, everything is asynchronous.
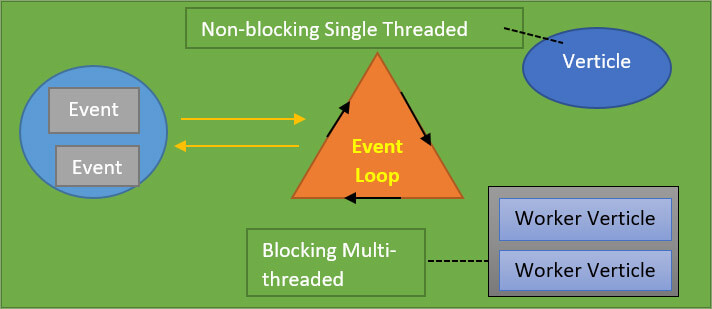
So, this model of asynchronous behavior it’s a reactive pattern and also the same which is implemented in node.js. So if you know node.js actually there is one thread processing or your application logic and for what that one thread your application is optimized to when there's any long-running work, the thread is not blocked but it's either running on a separate thread or it's an external system doing its processing and you use callbacks to further process your information.
Verticle Functionality
Although the application logic you write is asynchronous and this is an optimization. With vert.x you can use your processing power efficiently and because of the asynchronous model. Of course, when you start developing your software you always run into cases where you cannot do asynchronous processing. So, there are also utilities for using separate threads for instance. Everything in vert.x that does something is called a verticle.
If you have maybe a small rest service, you will write a vertical that implements this functionality and if you need to do any stuff on another thread, it’s called worker verticle. So, maybe you have to call a legacy database and with a legacy JDBC driver and this is synchronous communication.
There's also more interesting stuff like automatically the number of instances of each verticle is scaled to the amount of threads available. For example, if you have eight core CPU, then you get eight instances of your Verticle automatically. So, that's the asynchronous model.
Another unique trait I think is in the distributed nature of vert.x.
Reactive Event Processing
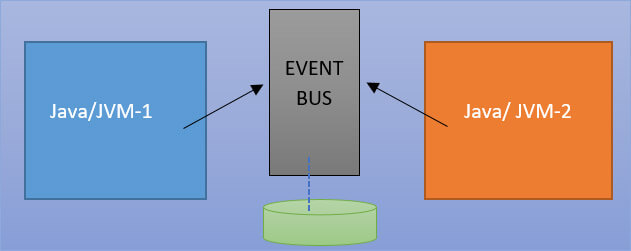
If you deploy your verticles in the communication between verticles, you use messages. And by default, these are JSON messages over TCP and the mechanism that you use to send the messages is called an Event bus and if you deploy in one JVM, it's just an in-memory thing. So, you send your messages in memory but if you deploy on multiple JVMs, it automatically creates a network i.e. cluster of nodes and the event bus becomes distributed.
Hazelcast
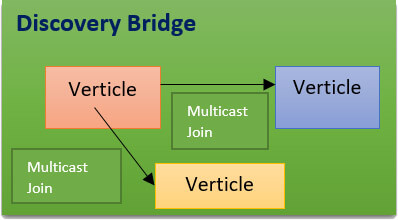
If you have an ideal network where multicast is allowed, so say for instance your laptop is on the same network as your colleague laptop, you will run a verticle here and your colleague will run a different verticle or the same vertical, they will automatically find each other using multicast join which is a Hazelcast function and you will be able to send messages.
Why Vert.x is Today’s Fastest Framework
Vert.x is ideally a good choice if you want to go for creating lightweight scalable high-performance microservices. If you have to do integrations with rest or other protocols, then it is really easy with Vert.x. It has distributed data structures. For instance, if you have to share your session data of multiple nodes, you can use the same mechanism that is used for messaging. So, underneath it uses Hazelcast which is like a distributed key-value store.
Vert.x for Java Microservices Architecture Implementation
In Vert.x 3.3, they have added more Microservices related features:
- Support of Circuit Breaker
- Http2
- Web client support
- Service discovery features
Circuit breaker Implementation with Vert.x:
High Availability and Fail-Over Management
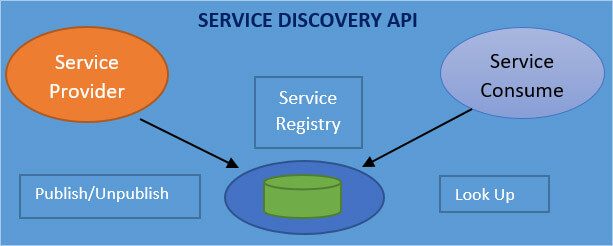
Service Discovery API:
Instead of having hard links between services you use the service registry and inside the service registry, every service provider registers itself and you can do this by name or by URL.
If you have multicast allowed on your network, different verticles can find each other. But in a lot of cases, this is not possible for instance if you run your services in docker they are already in a network environment where they cannot find each other.
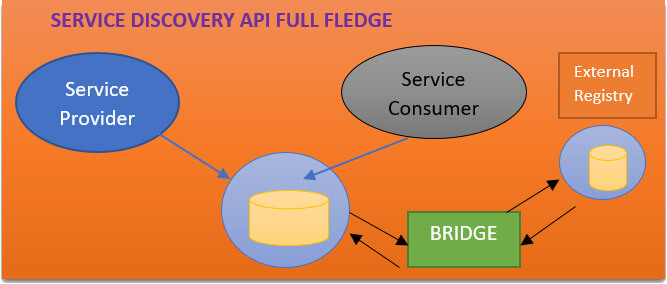
That's why the search registry is extended by a bridge and you can use an external registry. An external registry can be the Kubernetes registry, or it can be the zookeeper. You use an external method and one more thing you can do is you can mix with non -Vert.x services.
Say, for instance, you have a rest service and its built-in node.js or its built-in another Java language. They can register themselves in zookeeper or in the Kubernetes registry and which uses the bridge from your Vert.x verticles, you can find these rest services. You can import and export services with other registries.
This way of working of Dynamically Discovering Services:

Multicast enabled here so this means that the nodes will be discovered by providing the multicast IP: PORT bindings in the given network interface, as a result, any newly created node will publish the join messages all over the network so that it can be found with the given multicast group ID.
A use case: Implementation:
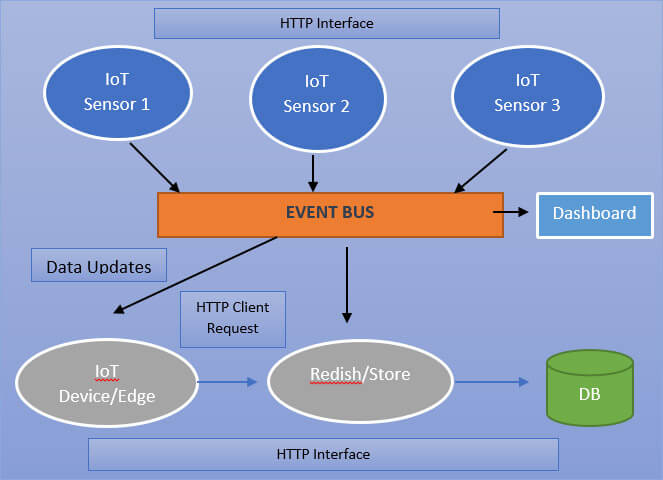
In the above diagram, each of these is a microservice and it's going to expose an HTTP interface and a very simple API we will be able to get their data from and whenever they update the temperature they will push an event to what we call the even bus and we will see what happens.
A second step would have another microservice which is going to look for all temperature updates and store this into a postgres database and it will also expose some queries over some HTTP API. In the third step we're going to have some gateway/edge service which is going to give us a simple API to get all the latest data or some very specific data. So, it's going to look for updates and maybe sometimes query the store services. And the last step we'll have some kind of dashboard. This is all achieved with Vert.x and Java microservices.

Recent Blogs
Categories


